
How I predicted the Giller Prize (and still lost the challenge)
This Fall we created a lab challenge to see if anyone could predict this year’s Giller Prize winner using a computer. The winner was announced last night, and it turns out I correctly predicted the winner. But I still lost the challenge. In this lies an instructive tale about humans, computers, and predicting human behaviour. Let me explain.
The rules for our challenge were straightforward. Given data about prizewinners and jury members over the past ten years, could your algorithm correctly predict last year’s winner and this year’s. (Since you have a 1 in 12 chance of guessing correctly once the long list is announced, we wanted to lower the odds a bit.) My algorithm predicted André Alexis’s Fifteen Dogs, which was the winner of this year’s prize. However, if you go to my earlier post and look at our predictions, you’ll see he isn’t listed anywhere. Here’s how I predicted his book correctly and why I changed my answer.
First, the prediction.
As we’ve learned over the past year, identifying what makes a literary prizewinner stand out from the pack is actually quite challenging. This is somewhat surprising as one of the things we have been learning in our lab is just how formulaic writing is in general. We can predict novels out of a pool of random books very easily (with about 95-96% accuracy), just as we can tell the difference between certain types of novels, say Romances and Science Fiction, with a high degree of accuracy (usually around 98%). We can even predict bestsellers, though currently not nearly as well (around 75%), though I suspect that number could improve with more work.
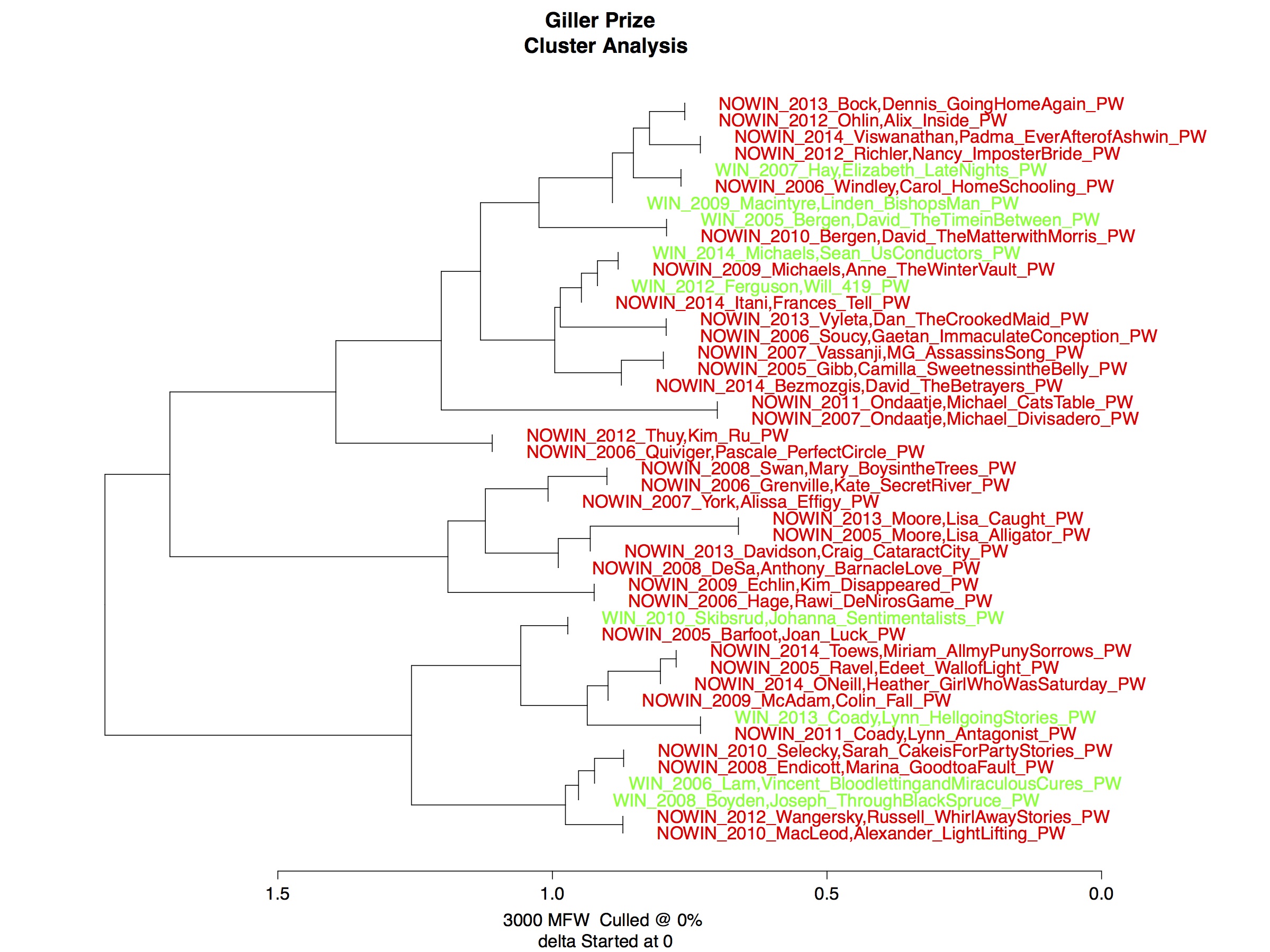
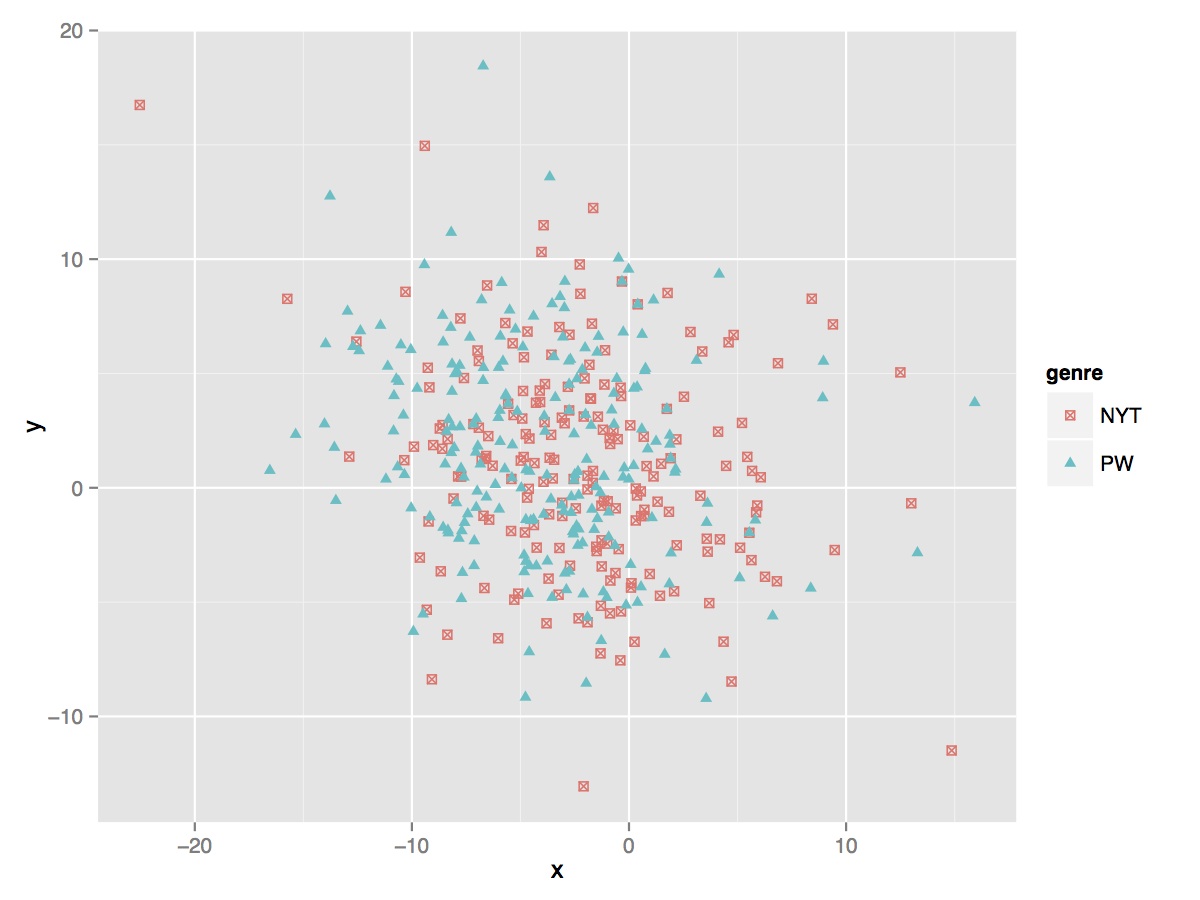
Prizewinners, on the other hand, present a different story. At the bottom of this post are two graphs that show just how unclear the distinctions are between prizewinners and their next of kin (non-winners).
But this messiness begins to clear up if you approach the problem not as one of similarity — what do prizewinners have in common? — and look at it as one of dissimilarity. What do prizewinners do differently from other books, including previous prizewinners.
The way I modelled the winning novel over the past two years was simply to look for the novel that was the most dissimilar from previous prizewinners and jury members’ own novels (based on about 80 different linguistic features which are based on the Linguistic Inquiry Word Count Software). Instead of looking for those prizewinning features that all novels have in common (make ’em cry Johnny!), I began to think about the problem as one of modelling human behaviour. It turns out, at least in this instance, jury members are looking for something fresh, something they haven’t seen before, either in past winners or in their own writing. André Alexis’ Fifteen Dogs is just such a book.
Now here’s is where the human operator comes in and messes everything up.
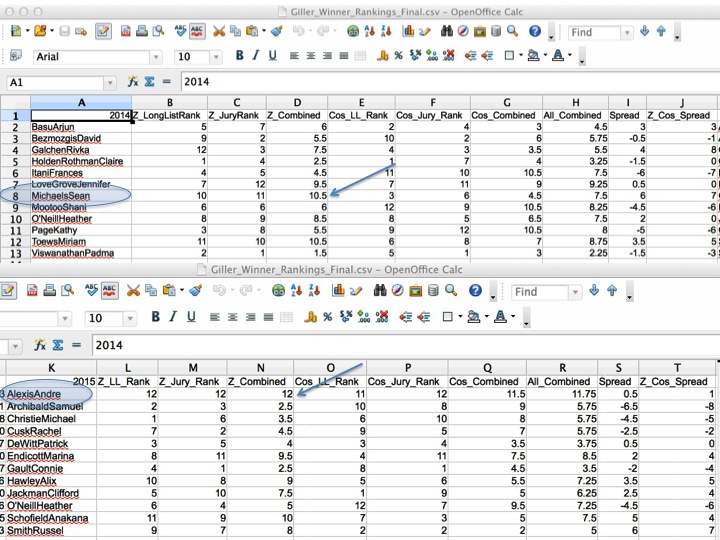
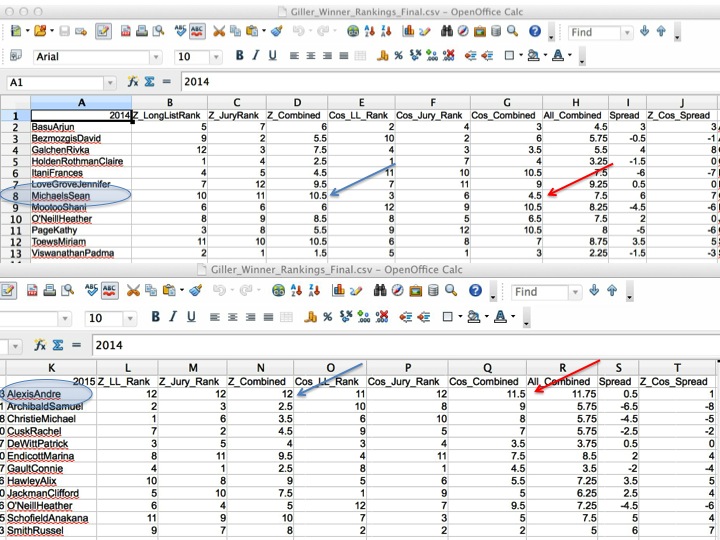
As you can see in the figure below (fig. 1), both André Alexis and Sean Michaels (the past two winners) rank lowest in terms of being similar to previous winners and jury members. Ok, I was done. Being curious, however, I wanted to review my findings, so I went ahead and read the book! Instead of this helping, it actually messed things up. For those who have read Fifteen Dogs, you will know it is a whacky, intense, challenging book. It is great and wild. My human intuition told me no prize committee would ever pick such a challenging book. I’ve sat on prize committees before. I’ve read a lot of prizewinners. I didn’t think this could happen.
So instead of being satisfied with my answer, I went looking for data to back me up. If you look at the second set of columns (fig. 2) you see a different way of measuring similarity. And there Sean Michaels didn’t look so unique. André Alexis still did. That second measure was a kind of reality check that assessed just how different people’s writing styles were from each other overall. Sean Michaels wasn’t radically different from his peers, but Alexis was. So I added another filter that said, you have to be the most dissimilar according to the first measure, but near the mean for the second. What this said was that you needed to be dissimilar to previous years’ winners, but not too far out in terms of style.
I was modelling human behaviour according to my theory of committees. It turns out I made a bad choice. And now I get to be forever known as the guy who predicted the Giller Prize but doesn’t get to take credit for it because he second-guessed the computer.
Why does any of this matter? Because it shows just how involved humans are in the process of data modelling. I made those initial choices to correctly predict the winner. The computer was a useful tool. I then thought more about my problem, looked more closely at the data, and decided to model my problem differently. The computer was still a useful tool, only my thinking about the problem no longer was.
Let’s say Martin John, my final prediction, had won. I’d look like a genius (or whatever) for having constructed my model to take into account expectations about group behaviour. But it turns out I didn’t do a good job of anticipating this group. That’s either bad luck or means I needed more data about how small groups make decisions.
Why do I love this work so much? Because it shows us how human behaviour is so unpredictable, whether it is the work of committees or data scientists. This is especially true when it comes to deciding which novels we love to read.
3 Comments
Join the discussion and tell us your opinion.
[…] touched base on a couple of similar problems, including Andrew Piper’s prediction of the Giller Prize. We also discussed the recent discovery of Dickens’s annotated set of the journal All the […]
[…] local Quebec writers try to impersonate a bestseller using our data and our successful attempt at predicting this year’s Giller Prize winner that was foiled by my misjudgment of committee […]
[…] local Quebec writers try to impersonate a bestseller using our data and our successful attempt at predicting this year’s Giller Prize winner that was foiled by my misjudgment of committee […]