
Development of a (Semi-) Automatic Character Network Tool
This is the third post in the series of .txtLAB intern projects. It is authored by Tristan Dahn.
The concept of social network analysis – initially rooted in classical sociology and more recently in the social scientific, mathematic, and computer science realms – dates at least as far back as the mid 1960’s [7]. Classically, social networks can be thought of as the invisible bonds that connect one person to another, and through degrees of separation, how tightly woven lattices of interactions can be imagined in order to examine a given social structure [7]. The analysis of character networks then, is an extension of social network analysis into the realm of literary analysis.
As with many modes of inquiry familiar to us within the humanities, social network analysis in the literary realm “begins with the primacy of character as its object of study.” [6 p.2] As such, if a network is composed of vertices and edges, and a story composed of a plot, it’s characters and their actions, then a literary character network is composed of the characters as vertices and their interactions as edges [3]. Here is an example taken from an article by Franco Moretti on network analysis from the New Left Review for a character network in Shakespeare’s Hamlet [3]:
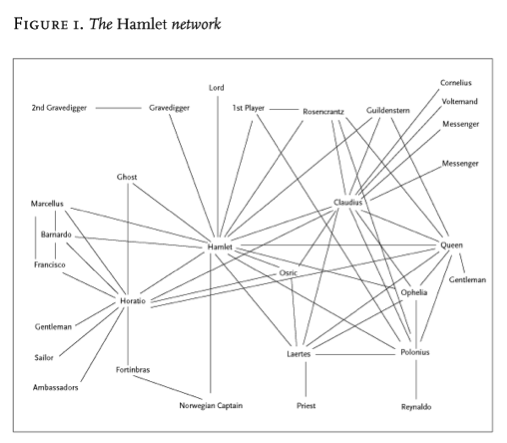
For Moretti, this is “time turned into space” [3]. All concepts of fabula and sujet are disregarded and reduced to a flat representation. It is a “character-system arising out of many character-spaces“, in which the “past is just as visible as the present” [3]. What we are looking at then, when we examine a character network is no longer the text per se, but rather a model of the text [3]. An interpretation then says little about the author’s actual words, but rather it looks at the underlying structures of the text [3].
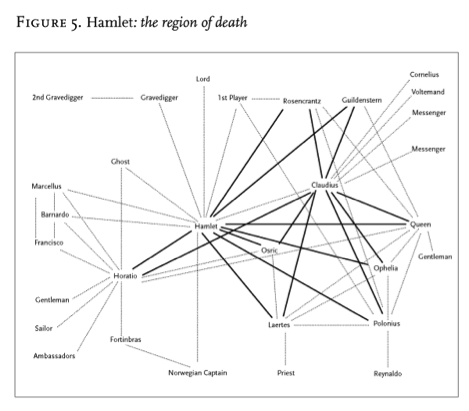
“It’s like an X-ray: suddenly, you see the region of death of Figure 5, which is otherwise hidden by the very richness of the play.” [3]
Additionally, Moretti reminds us, character networks are not simply observable, they are alterable [3]. By creating a model, we are creating a system with which we can “experiment” [3]. These experiments in turn can shed new light on the underlying structure of texts. An example offered by Moretti is the removal of central figures from a text [3]. So what does Hamlet without Hamlet look like?
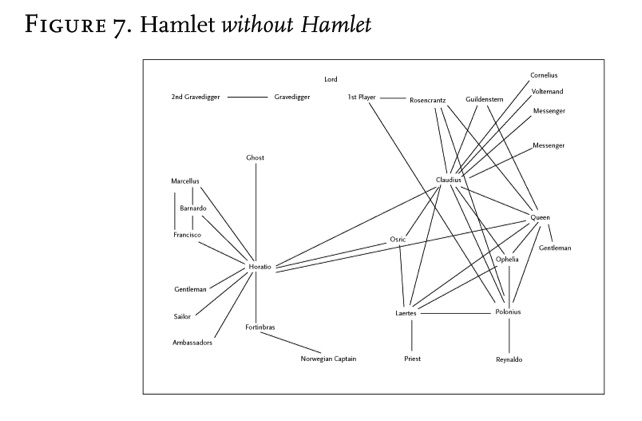
From this, Moretti asserts, we can see that what is so important about a protagonist is not simply their essence, but also their centrality, for they are what holds the broader network, and as such the under lying structure the narrative together [3]. In looking closely, we can see that in this play, with the removal of just three characters, Hamlet, Horatio and Claudius, the entire structure of the narrative would collapse. In character network analysis then, the place of any character in a narrative is defined through their relationships with the other characters in the narrative, and is not indicative of the character based solely on traits [6].
Development of a Character Network Tool
Character Networks may be valuable tools for helping literary theorists examine the structure of texts, but the construction of these network maps is often very time consuming. Given trends in the digital humanities toward big data type analysis of larger and larger corpora, a program for aiding in the creation of character network maps could be a valuable addition to the digital humanists’ vastly expanding tool-kit. (For the purposes of this script, an interaction, which constitutes a connection between characters and contributes to edge width, is represented by a co-occurrence of character names within a given paragraph.)
In this section I will explain step by step the development of such a tool in iPython Notebook for the mapping of character networks. iPython notebook is a browser based tool for writing and experimenting with Python scripts, as well as inserting text and multimedia annotations. These “notebooks” can be viewed online as webpages using the nbViewer hosted on GitHub. For this section we will have to take a quick detour from the .txtLAB blog and look at one of these notebooks:
(Additionally, you can download the notebook and use the scripts for your own purposes, however you will need iPython installed, which can be done by following the directions here: http://ipython.org/install.html.)
Here is an example of the results that can be outputted, taken from the first two chapters of Kazuo Ishiguro’s Never Let Me Go:

Testing and Validation
We can see that the tool is providing us with results that look good, but in order to be sure that it can be used for analyzing texts we must show some numbers in order to understand what the effectiveness of the tool, and what the trade offs might be. For this purpose I have chosen three novels to look at, which I have chosen for the difference in narrator perspective, and because I have read them before. These are Never Let Me Go by Kazuo Ishiguro, The Brothers Karamazov by Fyodor Dostoyevsky, and Freedom by Jonathan Franzen.
The first metric I looked at was recall and precision in terms of the interactions between characters for the story modeled above. Precision and recall are concepts that come from the field of information retrieval. Let’s first imagine the four cases for which retrieved information relates to its relevancy, in terms of character interactions. That is true positives (TP), a case in which an interaction is captured by the algorithm, false positives (FP), a case in which an interaction is registered when there actually was none, false negatives (FN), the case in which an interaction occurred that was missed by the algorithm, and true negatives, the case in which no interaction occurred and no interaction was registered.
Precision is a measure of the accuracy or information returned by a particular information seeking behavior. It is calculated by dividing the number of relevant retrieved items by the total retrieved items. In our case of character interactions, it is calculated as TP/TP+FP. Recall is calculated by dividing the number of retrieved relevant items by the total possible number of relevant items. In our case of character interactions, it is TP/TP+FN. For a visual representation of these concepts, the Wikipedia page on precision and recall is quite useful.
Now how to calculate these for the texts that I’ve chosen for testing? The answer is, unfortunately for me that this must be done by hand. Remember the structure of the interaction dictionary from the script? In it the paragraphs are numbered, and the characters in each paragraph listed. For the purposes of comparing these lists to each paragraph I have written a quick script that spits out each paragraph as its own numbered .txt file. This makes it relatively easy to look at the “hits” (occurrences of characters) paragraph by paragraph to check whether these match with a close reading of the text. For an idea of what this looks like, the following image is provided from test work I did on the Sherlock Holmes corpus:
Never Let Me Go:
Precision: 0.95876288659794
Recall: 0.87735849056604
Freedom:
Precision: 0.8962962962963
Recall: 0.86428571428571
The Brothers Karamazov:
Precision: 0.84883720930233
Recall: 0.74489795918367
So we see that, in these instances, in terms of precision and recall the results of the NER detected character dictionaries is quite good. However, it should be noted that for certain texts this process my not work as well. In previously looking at the Sherlock Holmes corpus, the recall was significantly lower because there are many characters in those stories that are not given proper names, but do have significant roles, such as “the country doctor”, “the station master”, and “the stable-boy.” Character entities such as this will not be detected by NER, and as such are excluded from its results entirely, which occurred for one character in The Brothers Karamazov as well.
Another measure of success is to compare the centrality of characters as determined by the NER edge list with an edge list that is made based on a close reading. To do this, I reread each section, incrementing each character pairing’s edge whenever they interacted during the course of a paragraph. In comparing the results from the three text sections in terms of strength, a weighted centrality value, we see a fairly minimal amount of shifting, and in most cases the strength value is close for each character, even if the basic order changes.
| Freedom | |||
| NER | Close reading | ||
| ID | Strength | ID | Strength |
| 6 | 57 | 6 | 53 |
| 20 | 48 | 20 | 36 |
| 8 | 43 | 8 | 30 |
| 1 | 27 | 2 | 23 |
| 21 | 26 | 21 | 21 |
| 2 | 26 | 1 | 18 |
| 14 | 20 | 14 | 15 |
| 3 | 14 | 3 | 13 |
| 5 | 9 | 5 | 7 |
| The Brother Karamazov | |||
| NER | Close reading | ||
| 16 | 38 | 16 | 40 |
| 4 | 34 | 4 | 34 |
| 6 | 27 | 6 | 24 |
| 11 | 21 | 1 | 22 |
| 1 | 19 | 11 | 22 |
| 7 | 19 | 7 | 13 |
| 2 | 11 | 2 | 13 |
| 18 | 10 | 8 | 10 |
| 8 | 5 | 18 | 9 |
| 20* | 5 | ||
*Character 20, “the general’s widow” not captured by NER.
| Never Let Me Go* | |||
| NER | Close Reading | ||
| 5 | 57 | 5 | 58 |
| 8 | 49 | 8 | 42 |
| 13 | 26 | 13 | 31 |
| 1 | 8 | 1 | 7 |
| 12 | 4 | 12 | 5 |
| 11 | 4 | 3 | 4 |
| 10 | 4 | 9 | 4 |
| 23 | 4 | 11 | 4 |
| 2 | 3 | 2 | 3 |
| 3 | 3 | 4 | 3 |
*Never Let Me Go contains many minor characters, some were captured by NER and some were not, as well the interactions among these minor characters varied from the NER and Close reading edge lists. This accounts for the differences between the strengths above in the 3 to 4 range.
Conclusion
It seems to me then, that if one is concerned more with the action of the principle characters of a narrative, using NER technique may be a valid way to generate character networks from a text in a way that still represents the basic underlying structures of the text. As discussed above, these networks are not meant to represent the text, but are instead models of the text for us to experiment with and make interpretations and insights from [3]. The centrality of the most central characters is certainly not lost using the NER process, and as such much of the fundamental structure as revealed by the network model may still be in tact. As such, it is up to the individual researcher to determine the trade offs in the context of their research to determine if this method is suitable for their needs.
References:
[1] Brill, Eric. “Transformation-based error-driven learning and natural language processing: A case study in part-of-speech tagging.” Computational linguistics 21, no. 4 (1995): 543-565.
[2] Carrington, Peter J., John Scott, and Stanley Wasserman, eds. Models and methods in social network analysis. Vol. 28. Cambridge university press, 2005.
[3] Franco Moretti, “Network Theory, Plot Analysis,” New Left Review 68 (2011)
[4] Nadeau, David, and Satoshi Sekine. “A survey of named entity recognition and classification.” Lingvisticae Investigationes 30, no. 1 (2007): 3-26.
[5] Newman, Mark. Networks: an introduction. Oxford University Press, 2010.
[6] Piper, A., Ahmed, S., Al-Zamal, F., and Ruths, D. “Communities of Detection: Social Network Analysis and Detective Fiction.” (2014)
[7] Scott, John. “Social network analysis.” Sociology 22, no. 1 (1988): 109-127.
[8] Sinclair, Stefan. “Notebook on Nbviewer.” 2015. Accessed April 16, 2015. http://nbviewer.ipython.org/gist/sgsinclair/bf112f84f130c8bac96c.