

The Constraints of Character. Introducing a Character Feature-Space Tool
What is it that we do with characters? And what do they do for us?
Different schools of literary theory have provided different answers to these questions. For the Russian formalists, character was above all else a “type,” one that served different narrative functions, a move that has been recently reawakened in the field of computer science in the great new work of David Bamman and Ted Underwood. For poststructuralists that came in the wake of Propp, character was instead a rhetorical “effect,” one more example of the referential phallacy of naïve readers. Characters were ambiguous semantic bundles, neither types nor individuals.
Alex Woloch’s work, which builds substantially off Deidre Lynch’s closing chapter in The Economy of Character, has emphasized a more distributional understanding of character, the ways in which the asymmetrical contrast between major and minor characters draws attention to a larger problem of social integration, of the one and the many in his words. Lisa Zunshine’s work, coming out of the field of cognitive science, has argued that characters, far from being rhetorical constructs, are models of “theories of mind,” means for learning about and hypothetically experiencing human cognition. We identify with characters, according to Zunshine, one mind to another.
Finally, Lynch’s work on character was instrumental because of the way it realigned our sites around the historically specific uses of character, the way round and flat characters were not to be understood normatively, as a movement towards some higher good, the deep character, but instead addressed historically specific concerns of eighteenth- and nineteenth-century readers. In this sense, characters still have functions, just not typologically as in Propp, nor are these functions related to the aim of psychological mirroring as in Zunshine; rather, the function of characters are more socially constructed, serving the contingent contextual needs of readers at given points in time.
Today I’m going to be making a different argument about what I think characters are for, one that is based on using computational methods to study character. Computation is an important tool to understand character because of the way it changes the scale of our understanding of the problem in two important ways: first, it allows us to talk about a much larger number of works in order to test the generalizability of our claims about character. With the exception of Propp what all of the works mentioned above have in common is that their insights about character are gleaned from a handful of individual examples. There is a disconnect between our evidence and our claims that sooner or later we are going to have to reckon with, and not just when we talk about character.
Second, and perhaps more importantly, computation changes the scale of our understanding of character in the sense of the lexical universe of characters. Like other highly frequent textual features such as conjunctions or punctuation, characters are abundant, or we might say highly distributed, not just in the world of fiction more generally, but across the pages of individual novels. Pronouns alone account for over 16% of all tokens in a novel, which if you add in proper names the number of character occurrences is closer to 20%, or one in every five words! (For reference sake: Verbs represent about 14% of words, conjunctions about 6%, and periods 7%). There is a tremendous amount of information surrounding characters in a given work that our traditional methods are simply not well equipped to account for.
This paper, and the larger project to which it belongs which I am working on with my graduate student Hardik Vala, is about trying to account for this lost information. Specifically, I am interested in better understanding the language associated with characters, what we might call the “character-text” of novels. To what extent do these textual spaces distinguish themselves from other aspects of novels and to what extent can characters be thought of as forms of distributed consciousness, as greater manifestations of the thought of the novel? Is there a unique “character space” in the novel, and if so, how does it work? Finally, how well differentiated are characters from one another or from themselves over the time of the novel? Should we be thinking about characters as distinct entities or one larger semantic space of “characterization,” a kind of super-ego to the novel’s ego (or Id)? These questions are motivated in part by a new push in the field to think about novels less as unified entities and more as consisting of different kinds of texts within themselves, a more precise form of Bakhtinian heteroglossia. The recent work by Mark Algee-Hewitt and Marissa Gemma on dialogue falls within this, where dialogue can be seen as a related, and yet similarly distinct textual entity within the novel from the space of character itself.
My project began with the frustration that I mentioned at the beginning of our panel about the flatness of our narratives about the rise of round characters. The metaphorical confusions about roundness versus depth suggest to me that there is a good deal of conceptual ambiguity surrounding exactly what we meant when we talk about deep (or round) characters. Instead, I wanted to think about developing a more multi-dimensional understanding of character, a kind of character feature space, that is able to capture different aspects of how characters are developed in a text and how they function over time, what I would call for lack of a better word the larger process of “characterization.”
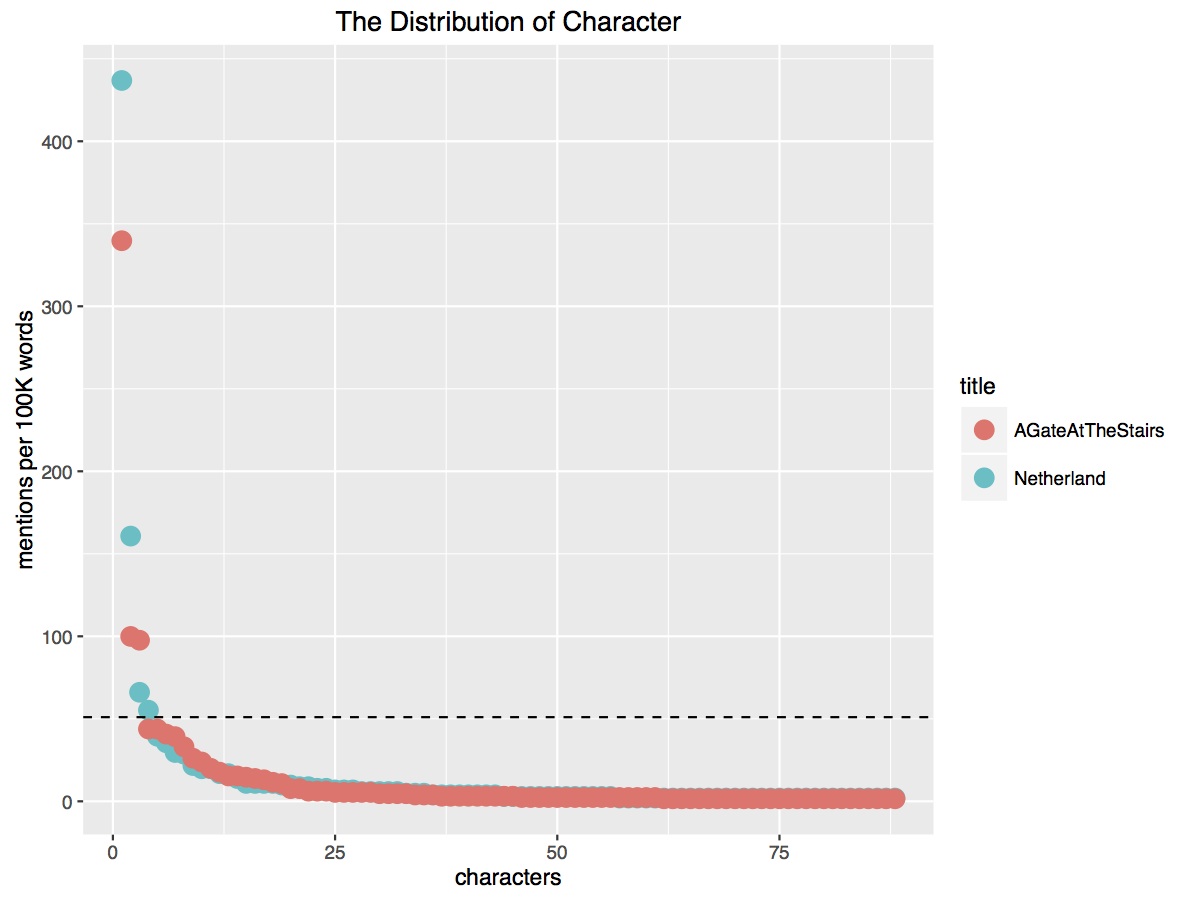
Rather than think in binary terms about deep versus shallow, I want us to think in more relational terms about the ways in which characters matter through the positions they take, the modes of behavior in which they engage, and relative distinctiveness through which they are semantically encoded – the extent to which they are literally “embodied.” Characterization for me isn’t principally about looking at different characters and their roles (the hero, the villain, etc) – so many acts of linguistic personification. Nor is characterization exclusively captured in the economy of character that Lynch and Woloch have discussed – the highly skewed distribution of characters within a novel that we see in the image below. Rather, my interest is in capturing this economy in a broader sense: the different positions that are occupied by characters, the different modes through which they behave, and the relative distinctiveness through which they are semantically embodied.
What I would like to present today is our list of 25 different features that we have examined in a collection of roughly 7,000 novels. To do so we took the following steps:
- First, we identified characters and as many of their aliases as possible using a modified version of David Bamman’s bookNLP.
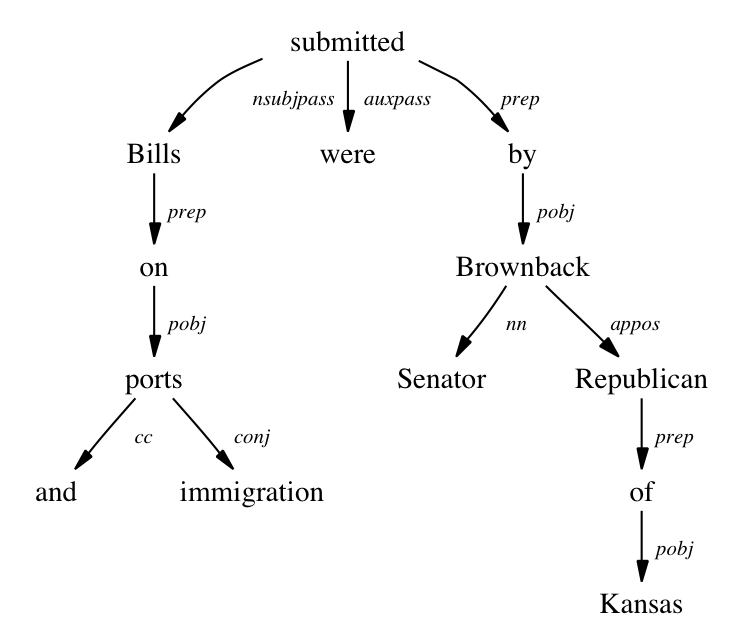
- Second, we extracted words associated with characters using the Stanford dependency parser, which identifies words that stand in “dependent” relationships with characters (the verb when a character is a subject, a modifier when the character is an object, etc – there are sixteen different relationships we capture).
Here is an image of how the parser breaks down a sentence into dependency relationships:
These steps are of course not error-free. Some character mentions are inevitably be missed (about 18%). And the dependency parser for its part has what we call high precision and low recall – the words it identifies are just about always modifiers of characters, but it misses plenty of words (the other method one can use is pointwise mutual information on a window of words around character mentions which has high recall and low precision — it gathers a lot of words that have nothing to do with characters).
To give you a real-world example, here is a sample sentence from To the Lighthouse followed by the list of the extracted dependency relationships:

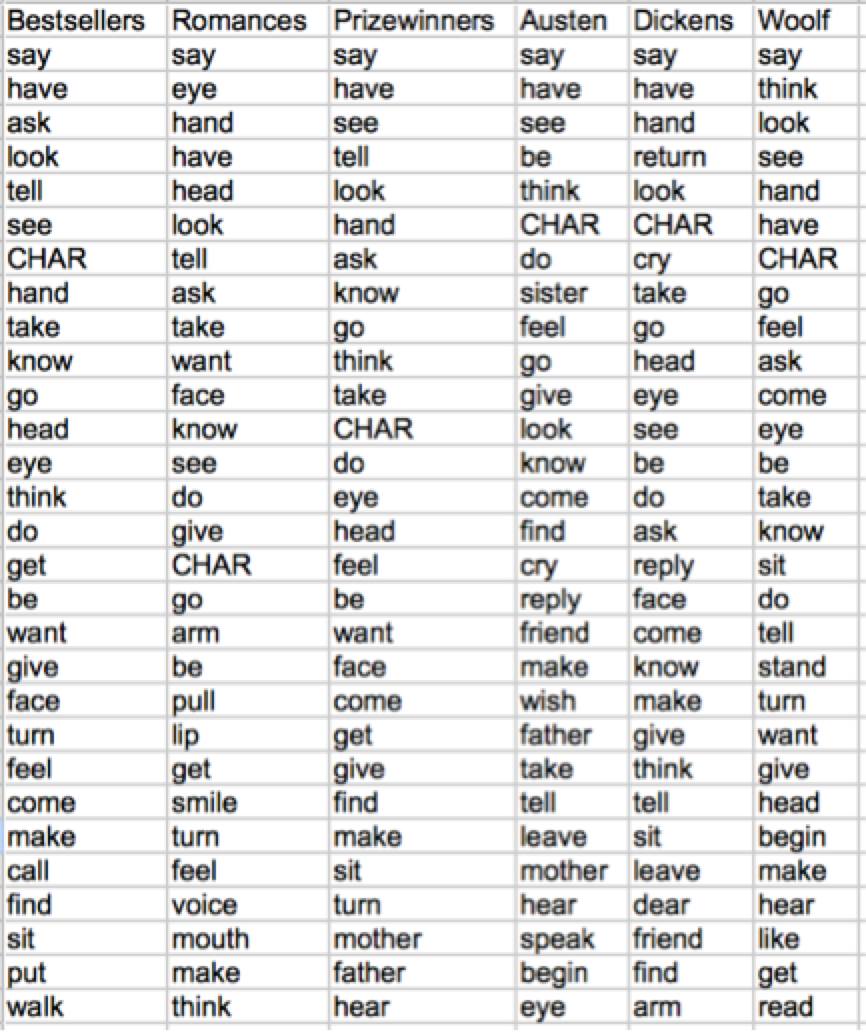
And here is what those individual acts of parsing look like when aggregated. Below is a table of the most frequent words that appear in dependency relationships with characters from different subsets of writing. As I will discuss, the similarity at work across the different distributions are going to be our main area of focus.
Following the work of Bamman and Underwood, we are interested in studying character according to four primary positions:
- Agent (what characters do)
- Patient (what they have done to them)
- Possessor (what they possess)
- Predicate (how they are modified)
Based on these four positions, we look at the following features:
Distinctiveness
- Distinctiveness A. How distinctive is the vocabulary around characters? Our measure looks at skewness, i.e. how few words account for more of the information around characters.
- Distinctiveness B. Our second measure uses KL divergence between non-character words for a novel and character words for top 500 most frequent words.
- Homogeneity. How similar are characters to each other in the novel. Takes pairwise cosine similarity on top 5 character vectors.
- Class Similarity. How similar are characters to the mean character vector of their class.
- Breadth. How much semantic diversity is there in the vocabulary around characters (using avg. distance between wordnet classes)?
Positionality
- Agent. What % is a character the subject of a sentence?
- Patient. What % is a character the object of an action?
- Possessor. What % is a character possessing something?
- Predicate. What % is a character a predicate?
- Sociability. What % is a character both the subject and object of an action, meaning two characters are engaged in an interaction, i.e. a character is dependent on another character in his or her description?
- Polarity. What is the maximum difference in the sentiment score for any two characters (within the top 5)? I.e. how much conflict is encoded in character relations in the novel?
- Communicativeness. What % of dependency words are communication verbs (said, answered, etc). How much is character dialogue driven.
- Descriptiveness. What % of dependency words are adjectives?
- Objectivity. What % of dependency words are objects (as identified in the wordnet path under “physical entities”)?
- Abstraction. What % of dependency words are abstract values (as identified in the wordnet path under “abstraction”)
- Physical Description. What % of words concern physical characteristics.
- What % of words are about values?
Centrality
- Centrality. What is the ratio of the number of occurrences of the first and second character? I.e. how central is the protagonist to the novel?
- Ensemble. After the first character, at what rank does the maximum drop between character occurrences take place (between the 2nd and 3rd, etc). This tells us how large a leading ensemble is in the novel beyond the protagonist’s strength.
- Distributedness. What is the skewness of the distribution of character occurrences? The more skew, the more occurrences are weighted towards a smaller number of more central characters.
- Population. How many characters are there overall? Number of characters per 10K words.
Modality
- Perception. How many words are concerned with sensing?
- Cogitation. How many words focus on cognitive processes?
- Affect. Measures sentiment vocabulary.
- Embodiment. How much focus is there on body parts?
- Motion. How much and what kinds of motion do characters undertake?
The aim of this feature space is to capture and test different beliefs about how characterization has changed over time or between different kinds of genres. Our assumption is that we should see more distinctiveness over time as characters become “rounder,” more psychologization as they become “deeper;” decreasing inter-character distinctiveness around the modernist period as characters become dedifferentiated (Moses); less abstraction over the nineteenth century as characters became more concrete (this is the argument of Lynch for the 18C and Heusser and Le Khac for the 19C); an overall increase in characters in the realist novel of the 19C (Woloch); that certain genres should favor more “agency” in characters (such as bestsellers) or more “sociability” (ditto). We also felt that while these features may not replicate our standard periodizations or genre groupings, that we could detect new kinds of “character-genres,” not simply works that focused more on protagonists or ensembles, but different kinds of multi-dimensional groupings for which we didn’t yet have labels.
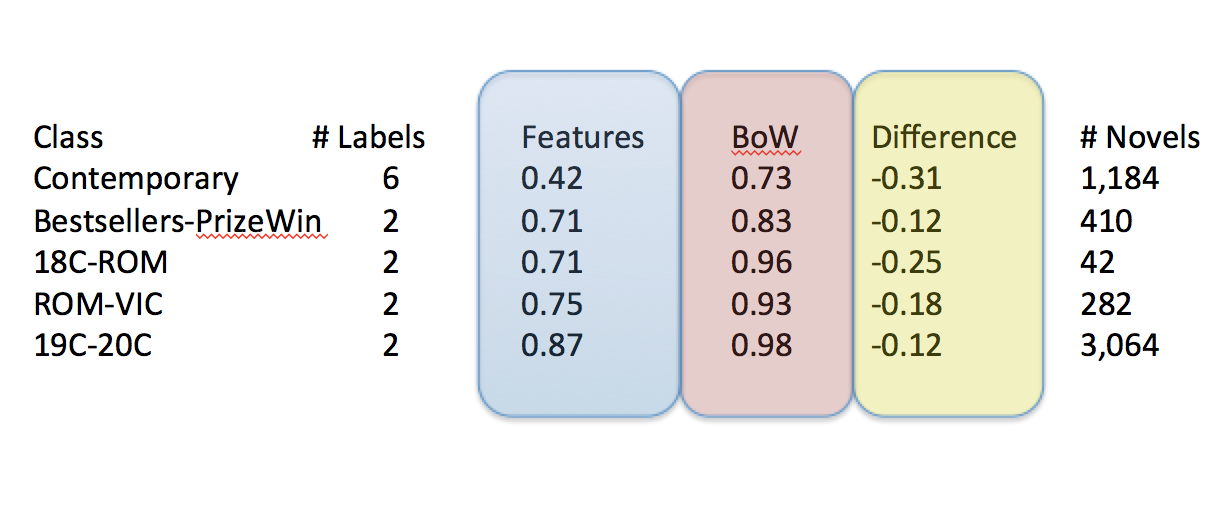
When we began to use these features to classify our texts, however, we saw a very strong decrease in performance relative to using lexical features drawn from the same works. In other words, in looking at character features, we lost a great deal of information when compared to the semantic features of the same novels.
Similarly, when we performed a standard clustering approach using principal component analysis, we found that these groups really do not seem to cluster well. (Nevertheless, there is some useful information in terms of how the features correlate and point in different directions. More on that later.)
Given the information loss that occurs when we model characters at these levels of position, behavior, and distinction, the question that emerged for us was, How much information do characters account for in a novel? While we know there is a high amount of data surrounding characters (all of these mentions with all of these dependency words), how much information does this data contain, where information can be understood colloquially as uniqueness and more technically as “uncertainty”?
To better understand this question, we reran the same tests only this time using words only drawn from the character vectors or words only drawn from the non-character vectors (i.e. we removed character words from the novels). The more unique information that a category contained (the character space v. the novel space more generally), the more it should help us distinguish between different types of writing. As we’ve seen, we have a baseline understanding of how semantically different these groups are from one another, which is generally very distinctive (the column BoW). The question is how characters contribute to this uniqueness.
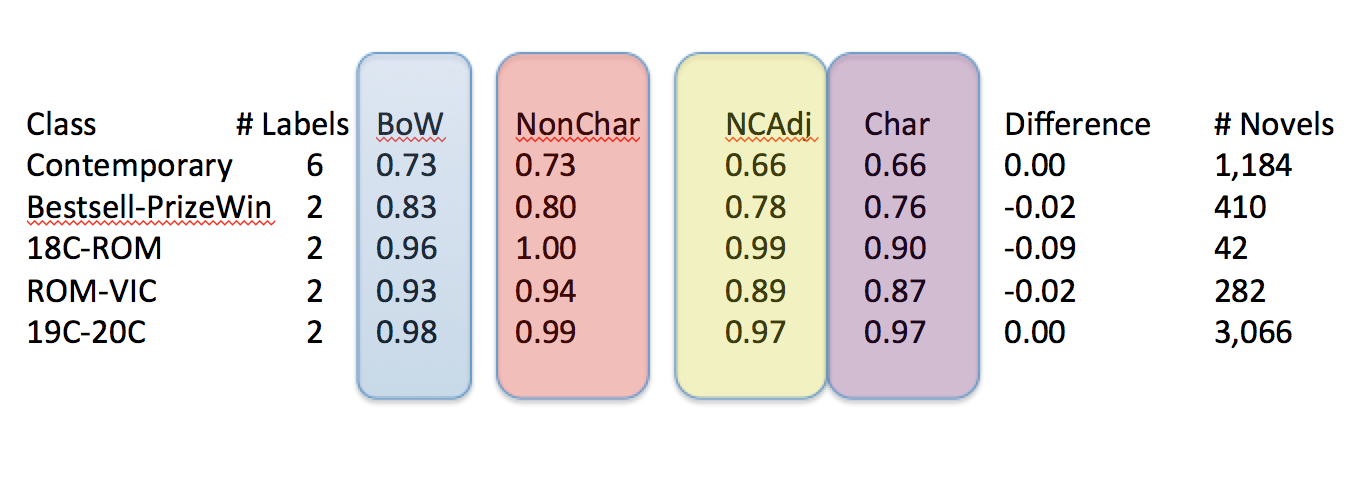
What’s interesting about these results is the way characters do not appear to contribute any unique information about the novels from which they are drawn. Not only do non-character words perform as well as character words when reduced to the same number of variables (NCAdj) (meaning we test the same number of words for each category), but when you simply remove characters from novels and keep the rest of the words (NonChar), the decline in predictive accuracy from using all words together (BoW) is generally negligible. Taking characters out doesn’t change much.
The second test we ran was to look at whether character vectors were more similar to other character vectors from novels from the same class versus comparing character vectors to non-character vectors from the same novel. In other words, we wanted to know whether characters are more similar to other characters or whether characters are essentially extensions of an authorial style. This time the difference was quite strong. Characters are much more similar to characters from other novels than they are to the novel language from which they are drawn.
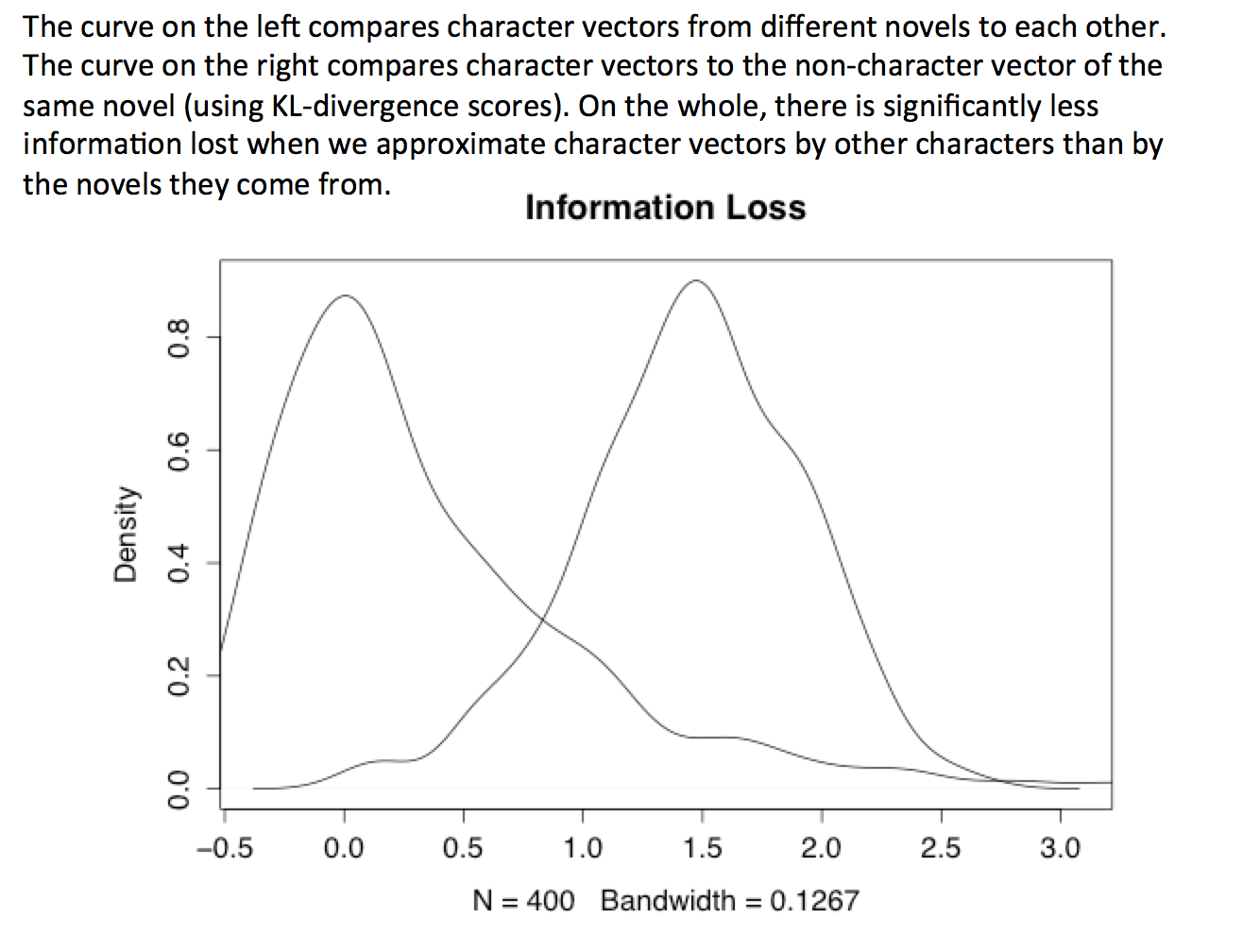
Taken together these various tests suggest that the character-text of novels has a kind of two-fold identity: it is both highly distinct from the rest of the novel from which it is drawn and highly similar to the character spaces of other novels. It either contains no extra explanatory force than the non-character space of a novel OR it decreases what we know about what makes novels distinct from one another (as in our feature space). Seen in this way, characterization is a privileged space within the novel, but one that performs a kind of symbolic generalization. Far from sites of individualization – character is where we go to experience uniqueness, difference, depth, individuality – character appears far more as a sign of the constraints of anthropomorphism, where humanization implies a reduction in representational diversity.
One of the things that seems to follow from this fact is that changes in characterization start to appear very slight except within very long temporal horizons. To come back to my initial slide about the performance of our feature space, there was one group for which the performance was relatively good and for which we can identify a variety of significant shifts in the practice of characterization, that between our broad 19th and 20th century groups. While I don’t have the time to explore this here, we can say that in general while practices of characterization do not seem to exhibit all that much difference between different genres of writing or even more related historical periods, they do seem to undergo some potentially significant changes across a much broader horizon of time (I say potentially significant because the results are not exactly overwhelming).
If we focus on just the most central character of a novel, we see how protagonists by the twentieth century become more central, more distinct, and yet also more similar to other leading characters in the novel, more communicative, more agential (and less predicative and possessive), and more perceptually or sensorially oriented. They are more clearly marked out as a position within the novel but less so semantically from other characters. As the novel progresses through time, the character space itself becomes increasingly distinct even as characters within this space grow increasingly homogeneous. Ironically, characterization manifests itself through its own internal dedifferentiation.
This post was originally delivered as a talk at MLA 2016. It is co-authored with Hardik Vala.
2 Comments
Join the discussion and tell us your opinion.
[…] Andrew Piper, “The Constraints of Character. Introducing a Character Feature-Space Tool,” MLA 2016 presentation (https://txtlab.org/?p=611) […]
[…] ask in literary studies. We’ll want to develop much more expanded feature-sets in the future, such as these, but for now LIWC gives us a way of generalizing about a text’s features that can help us […]