

Data, data, data. Why Katherine Bode’s new piece is so important and why it gets so much wrong about the field
Katherine Bode has written an excellent new piece asking us to reflect more on the data we use for computational literary studies. Her argument is that many of the current data sets available, which rely on date of first publication as a criteria for selection, miss the more socially imbedded ways literary texts have circulated in the past.
Her thinking is deeply informed by the fields of bibliography, book history, and textual studies, most importantly by the work of D.F. McKenzie. McKenzie was the one who first showed how New Critical reading practices that used modern editions to build their arguments missed the historical specificity of the texts they were analyzing. Instead McKenzie wanted us to think of the sociology of texts, the ways in which texts (as books, manuscripts, flyers, illustrations) circulate in social settings.
Bode’s intervention is coming at a crucial time. For people working in the field, there is an increasing awareness of the ways different data sets represent objects of study in different ways. We’re well past the days of believing that having “many” books solves the problem of historical representation. Bode’s piece suggests two important directions for future study, which I would put under the heading of “historical representation” and what Matthew Lincoln has called the problem of “commensurability” (perhaps also called the problem of “sample bias”).
Bode’s first point is that representing literary history as a collection of works with dates of first publication ignores much of the way those works existed in the world. Maybe they were reprinted numerous times, or anthologized in parts, or began as serial productions, or were heavily revised in later editions. In 1910, people did not only read books published in 1910. This circulatory identity of literature privileges in many ways a more “reader-centred” point of view. The question is less what texts did writers write when, but what texts were available for readers and in what forms. I have a whole book about the impact that material format plays on literary production in the nineteenth century, so I am deeply sympathetic to this point of view.
Bode gives us concrete ideas about how to build data sets that are more attune to these historical frameworks. “Fiction in newspapers” is the particular answer she gives, but there are plenty more options — looking at specific library collections, household collections, books that were reviewed in the periodical press, or bestseller lists or prizewinning lists in the twentieth century. These all put us in touch with the historical filters that impact when, where and how books mattered to readers.
As historians of reading know, however, just having a representation of what circulated does not quite get at “reading.” We still do not know what readers did with these books, how many of them were actually read, if they were read multiply, quickly, fragmentarily, gifted, regifted, shared, burned, or used as doorstops, etc. Bode’s suggested approach is important and useful because of the way it allows us to observe “textual availability” or even “textual circulation” in a specific time and place. But it is equally important to see how it as only one possible solution to the problem of historical representation that is more centred on reception than production. It does indeed orient us more towards a reading environment, but it stops short at being able to understand readers or reading. For this, other kinds of data would be needed (similar to my colleagues Matthew Erlin and Lynn Tatlock who have a new study out on reader behavior in a lending library in Muncie, Indiana).
If Bode’s example is both useful and limited in equal measure, the example she gives of the problem she wants to solve — the data set of first editions — is far less illegitimate than she makes it out to be. The aim of structuring data in this way is to focus on writerly behaviour — what stylistic tendencies were available at what points in time. Dating novels in this way is no different from a critical edition that organizes its poems by composition date — in each case we are trying to recreate the process through which writing changed over time, putting a fixed marker in the ground for every poetic output. Like the eclectic editions of previous traditions of bibliographers, such collecting practices try not to recover the textual environment in all of its complexity, but one regulated by a sense of temporal change. Such an approach overplays, to be sure, the historical specificity of texts and dates — did it all happen in that year? And as we know poets’ works change, too, so what about variants? Trying to capture writer behaviour through first editions misses all of the pre-and post-work that precede and follow publication, the messiness of creativity that was once upon a time the object of text-genetic criticism (a field that is interestingly not discussed by Bode).
But the point is, all data sets have limitations. Each data set will represent a set of historical transactions differently, and each has limits on what it can and cannot tell us about the past. A text-genetic approach will tell us something about the developmental process of works with respect to authors and their intervening agents of editors, readers, and booksellers. A first edition approach will allow us to approximate new items that enter into the literary field while ignoring questions of penetration and circulation (how many were printed, how many were bought, how many were read). And Bode’s approach will allow us to better understand this circulatory world of what’s “out there” at a given time in a given medium.
This brings me to the concerns I have with how the issue is framed by Bode. I would have thought it went without saying that using Moretti today to justify progress in the field is no longer acceptable. Want to find an outrageous quote that informs no one’s work today? Use Moretti. But if you want to understand what people are actually doing, then you need to turn elsewhere. Bode makes the claim that early practitioners did not share their data. Fair enough. But the new journal, Cultural Analytics, does. It is over a year old (full disclosure, Bode is on the board). We have an entire dataverse established where authors deposit their code and their data for others to use and review. I personally just released tables of derived data on over 25,000 documents from the nineteenth-century to the present, where the features used were drawn from LIWC. Again, it’s not perfect, but it’s definitely a start.
Similarly, to suggest that current cultural analysts imagine that their datasets stand unproblematically for some larger “whole” or population is an unfair representation. Ted Underwood tests multiple different sets of data according to different bibliographic criteria of selection in his piece, “The Life Cycles of Genres.” I test no fewer than 17 different data sets to better understand the uniqueness of fiction-writing in the past two centuries in my piece, “Fictionality.” Peter M. Broadwell et al test a single data set of Danish folklore, but they do so against previous scholars’ classifications to better understand how machinic labels (mis)align with scholarly judgments. In none of these cases do the authors think their data represents something stable or definitive. They are all aware of the contingency of their data sets in their ability to capture some aspect of history. And they build that contingency into their methodology. Of course we could do more, we can always do more. But we first need to acknowledge the existence of the work that is actually happening.
All of this was clearly stated (well, clear for me) in my introduction to the journal of Cultural Analytics, where I write:
This then is one of the major contributions, and challenges, of cultural analytics. Rather than abandon generalization, the task before us is to reflect not simply on the acts of cultural representation, of Auerbach’s notion of “represented reality,” but on the representativeness of our own evidence, to reconstruct as contingently as possible the whole about which we are speaking. Instead of embodying the whole like the cultural critic – having read the entire archive or seen all the images – the cultural analyst focuses instead on the act of construction itself. The cultural analyst is self-conscious about being implicated in the knowledge that is being created.
Similarly, in a piece from 2015, I tried to provide a model of the process of literary modeling that showed just how circular and contingent the relationship between part (data) and whole (history) was (Fig. 1). And I have a new piece forthcoming in PMLA that lays out the contingencies of representation that flow through the entire process of data modeling.
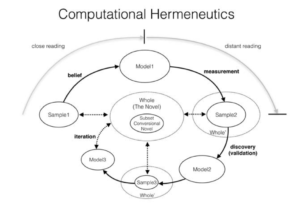
Once we acknowledge the contingency of data, however, a major issue is raised, one that, as Matthew Lincoln has pointed out, is omitted from Bode’s piece: that of commensurability. How can we assess how these various contingent representations relate to one another? What methods can we use to account for the different kinds of answers that different kinds of data representations give to our questions? Bode’s piece stops here, ironically suggesting that one data set is enough, the one she is building from Australian newspapers. It may be the case that she has access to “all” newspapers ever printed in Australia (though I’d be surprised). But are they all equally accessible in terms of textual quality (OCR) and what about other types of representations of fiction, say, books? Small presses? Manuscript circulation?
The point is that there is nothing wrong with the data set Bode wants to use, but in its singularity — in its singular standing for history — it risks running into the very same problem that she accused Moretti of. We absolutely need methods that reflect on the “representativeness” of data and how different representations differ. That is our job as cultural historians. From from being discredited through this point of contingency, data offers critical tools to make these assessments rather than take information at face value, like the New Critics did with their paperback editions.
If there is one larger point to take away from all of this it is that this whole process of data modeling is very messy and complicated. We really need to get past the discourse of finger pointing and move towards one that supports each other and acknowledges work that is being done rather than citing straw men from the past. Building data sets takes a lot of time. There are tons of interpretive questions built into the process. Feeling unsatisfied about a data set is the default, especially in the humanities given our very poor infrastructure for data. And building new methods takes a lot of time. There are tons of interpretive questions built into the process. Feeling unsatisfied about methods is also a default, especially given how rudimentary all of this is.
But waiting for the perfect data set or the perfect model is a bit like waiting for the white whale. And thinking that one set solves all problems is equally problematic. People should try to build data and models to answer questions they care about and be supportive of the work other people are doing. Its not going to happen overnight and there is no one right answer. Far from needing better data sets, we need a better discourse about how to engage with each other’s work, because there is a lot of on-going effort out there.
1 Comment
Join the discussion and tell us your opinion.
[…] goodness for purgatory busting colleagues like Sarah Stanley. There are better worlds – Andrew Piper and Matthew Lincoln’s responses to Bode demonstrate that. In that spirit I offer a general […]