
Are novels getting easier to read?
I’ve been experimenting with using readability metrics lately (code for the below is here). They offer a very straightforward way of measuring textual difficulty, usually consisting of some ratio of sentence and word length. They date back to the work of Rudolf Flesch, who developed the “Flesch Reading Ease” metric. Today, there are over 30 such measures.
Flesch was a Viennese immigrant who fled Austria from the Nazis and came to the U.S. in 1933. He ended up as a student in Lyman Bryson’s Readability Lab at Columbia University. The study of “readability” emerged as a full-fledged science in the 1930s when the U.S. government began to invest more heavily in adult education during the Great Depression. Flesch’s insight, which was based on numerous surveys and studies of adult readers, was simple. While there are many factors behind what makes a book or story comprehensible (i.e. “readable”), the two most powerful predictors are a combination of sentence and word length. The longer a book’s sentences and the more long words it uses, the more difficult readers will likely find it. Flesch reduced this insight into a single predictive, and somewhat bizarre formula:
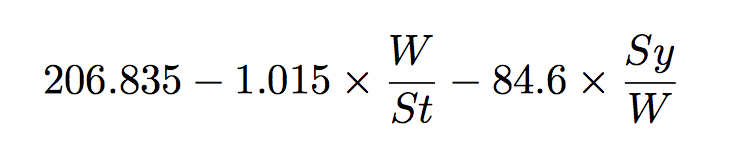
W = # words, St = # sentences, Sy = # syllables
According to Flesch’s measure, Rudyard Kipling’s The Jungle Book has a higher readability score (87.5) than James Joyce’s Ulysses (81.0). Presidential inaugural speeches have been getting more readable over time. The question that I began to ask was, have novels as well?
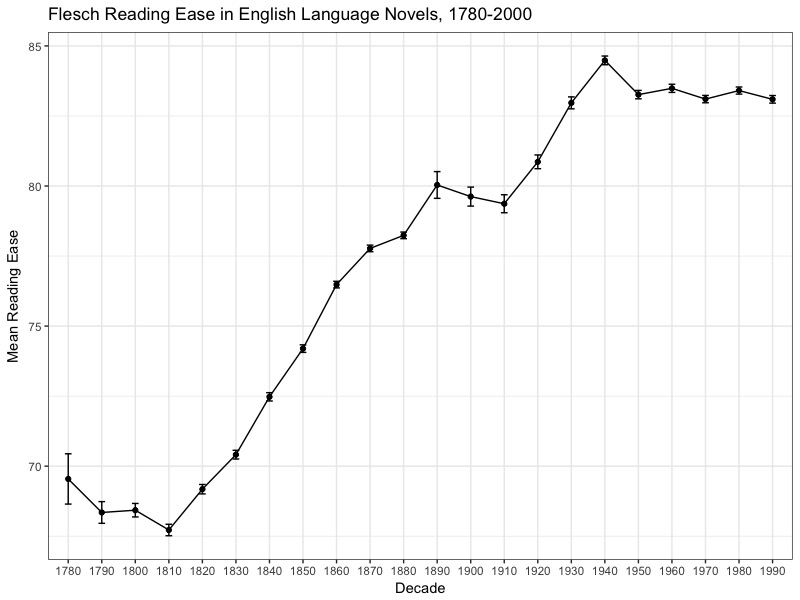
The answer, at first glance, is yes. Considerably so. Below you see a plot of the mean readability score per decade for a sample of ca. 5,000 English-language novels. These novels are drawn from the Stanford Literary Lab collection and Chicago Text Lab. The higher the value the more “readable” (i.e. less difficult) a text is assumed to be. The calculations are made by taking 20 sample passages of 15-sentences from each novel and calculating the Flesch reading ease for every passage. Then for every decade I use a bootstrapping process to estimate the mean reading ease for that decade. Error bars give you some idea of the variability around the mean per decade. What this masks is a very high variability at the passage level. Nevertheless, despite this the overall average is clearly moving up in significant ways.
One question that immediately came to mind was the extent to which these scores are being driven by an increase in dialogue. Dialogue is notably “simpler” in structure with considerably shorter sentences, and potentially shorter words to capture spoken language. I wondered whether this might be behind this change.
Below you see a second graph with the percentage of quotation marks per decade. Here I simply calculated the number of quotation mark (pairs) per novel and used bootstrapping to estimate the decade mean. As you can see, they rise in very similar fashion, though with a noticeable break where two data sets are joined together. Mark Algee-Hewitt has a lot to say on this issue of combining data sets. It’s interesting that typographic things like quotation marks are way more problematic for this issue than something more complex like “readability.” A lot also depends on my very simple model of modelling dialogue. It could just be that they get more standardized and thus appear more frequent, but I don’t think that’s entirely the case. Either way, this could definitely use improvement.
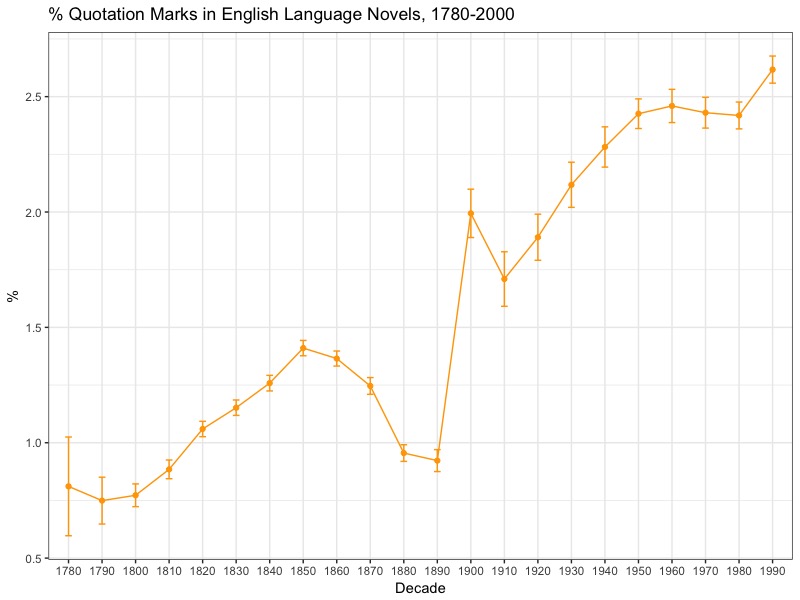
With these caveats in mind, there is a very strong correlation between the number of quotation marks used per decade and the readability of novels (r = 0.86). It suggests that dialogue is a big part of this shift towards more readable novels.
But what if we remove dialogue? Are novel sentences outside of dialogue getting simpler, too?
I don’t have an answer to that yet. And while it will be an important facet in order to nuance this issue, either way what we are seeing is how the novel, as represented in these two collections, follows a very straightforward trajectory towards simpler sentence and word lengths over the past two centuries. Much of that can be explained by greater reliance on dialogue, but that too is an important part of the readability story.
Why has this been the case? Commercialization, growth of the reading public…I don’t know. I think these are potential explanations but they require more data to show causality. What I can say is that based on the work I’m doing with Richard So on fan fiction is that fan-based writing — non-professional, yet high volume — does not exhibit significantly higher readability scores than “canon” does (i.e. the novels on which fanfic is based). In other words, in this one case expanding the user/reader base doesn’t correlate with simpler texts like you might expect.
It also looks as though readability has plateaued. Perhaps we’re seeing a cultural maximum being achieved in terms of the readability of novels. Then again, only time will tell.
* The other nice thing about readability is there is a great R package called koRpus to implement it. You can access the code through GitHub here.