
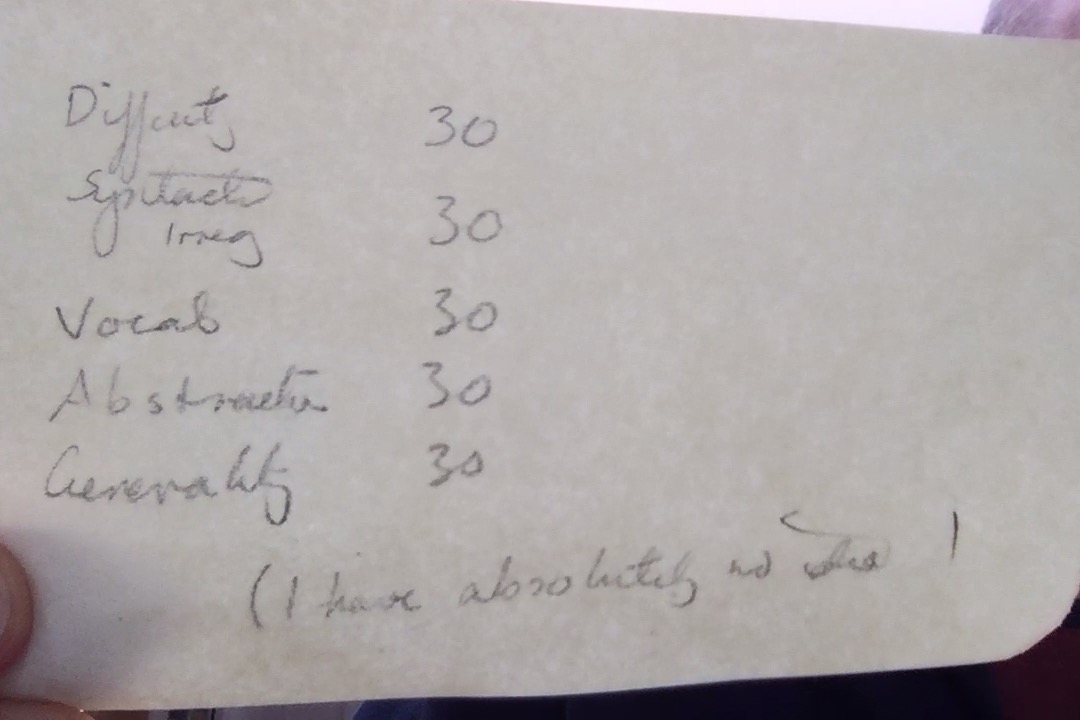
Did we already know that?
For anyone who has ever given a talk using computational methods the response, “But didn’t we already know that?”, looms large in your consciousness. Nothing feels more deflating…and frustrating. I always want to respond, well, we believed we knew it and now we have more evidentiary sufficiency to believe it even more strongly. But that’s a touch wordy.
I learned a fabulous technique from Lincoln Mullen who suggested using the trick of putting a blank graph or table up first and asking respondents to guess the results in advance. This is a fantastic way combatting the phenomena of “everything is obvious once you know the answer.”
I decided to go one step further at a recent talk. I asked respondents to write in their estimates for what I was measuring and then collected their responses. In other words, I wanted to measure “how much we already knew.” Here’s what I found.
First, my talk was about studying the idea of “late style” in poets’ careers. It is drawn from the last chapter of my book. The models I was building were based on Edward Said’s theory of late style that he develops in his posthumously published book by that name. In my reading of Said, I identified what I saw were 5 proxies for “challengingness”, which I saw at the heart of Said’s thesis. I then applied these measures to a collection of 78 poets for whom we have decent representations of their entire corpus. It is both a small and large sample — a small number of poets and a large number of poems (ca. 30,000).
After walking through the description of my five measures, I then asked the audience to fill in this table.

For each measure I asked them to estimate what % of the poets in my data set had a significant change according to that category in their “late period” (defined as the final quartile of their corpus). Significance was measured using a randomization test, ie. was the difference between the late and early poems greater than we might see in random fluctuations within the poet’s career overall.
I then asked them to estimate what % of poets who did have significantly different late periods whether they were more likely to increase their degree of challengingness or decrease (i.e. get simpler and more concrete). You’ll have to read the book for the full explication of the measures.
What I found when I tabulated the responses was the following:
A. About 1/4 of respondents made no answer at all (not including people who didn’t pass back their notes). Almost everyone reported that it was very hard to estimate.
B. In aggregate the crowd was very accurate. They were off on average by only 6.5% from the observed numbers (if we exclude the final measure which strikes me as erroneously low, i.e. a poor measure because it diverges so much from the others).
C. Individually, there was a really high degree of variance. The standard deviation was +/- 23 percentage points. In other words, the range extended from thinking a majority of poets had significant late styles to a strong minority. That’s basically two different answers.
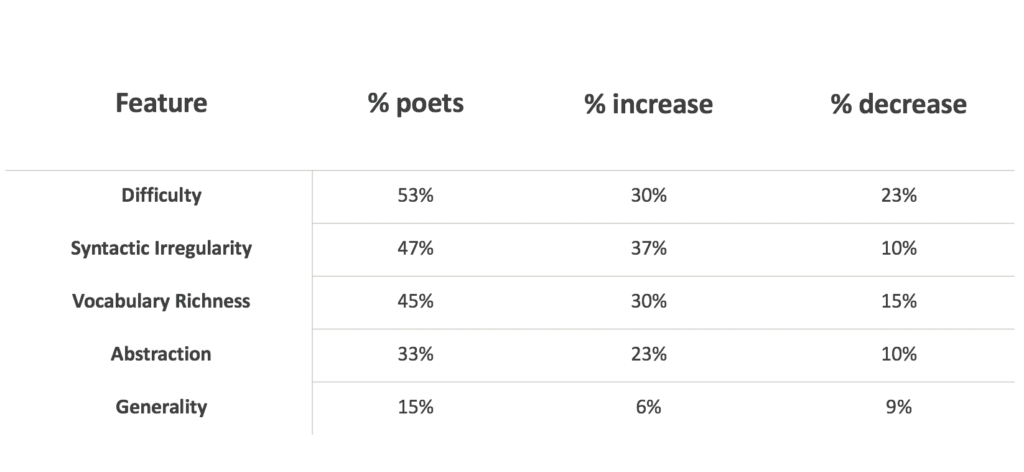
Below you see the observed results. Overall roughly half to less than half of all poets in the data set exhibited a significant change in their late work. Of those, most moved in the direction of becoming more, not less challenging.
What I like about this experiment is two-fold:
It suggests, first, that we actually do not have nearly as strong beliefs about measuring large-scale phenomena as we report after the fact. Pressed to put a number to something people became very hesitant. They were confronted with what they didn’t know and that they lacked the tools to be able to make an informed estimate. Second, it reinforces the idea that crowd-estimates can be very accurate in aggregate. One person might not know the answer but taking the average of all of our estimates will home in on the correct answer. Again, scale has advantages.
Some caveats: since the correct answer hovered around 50% there might have been a bias towards just saying “half!” which would be right in this case. On the other hand, it is obviously hard to make an estimate without intimate knowledge of the corpus and the measures being used. Lots of reason not to put too much pressure on that high variance. And last: everything depends on the data and the models being used!
But overall exercises like this can force us to confront, consciously and openly, the limitations of existing methods and why there is value to computational methods when it comes to trying to make generalizations about large-scale phenomena like poets’ careers.
Thank you to everyone at Berkeley for participating and being so gracious about it. It was a very fun way to interact with the audience.