Home
About
Publications
Data Sets
Home
About
Publications
Data Sets
.txtlab
A laboratory for AI and Storytelling
Loading posts...
Generative AI Doesn’t Replace Theory. It Makes Theory More Important Than Ever.
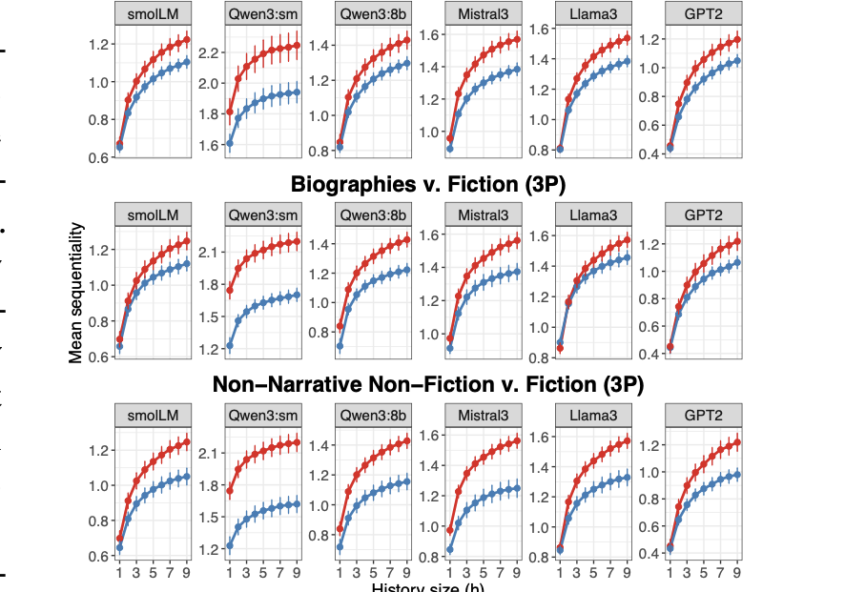
Do Fictional Stories Flow Better Than True Stories?
What can we learn from 28,000 historical children’s book illustrations?
New Citizen Science Project Launched: The Senses of Stories
What do novels teach us? Using AI to trace the moral history of the novel
Announcing a New Grant: AI for Cultural and Historical Reasoning
How Thousands of Citizen Readers Helped Build the Largest Open-Vocabulary Dataset of Narrative Emotions
Identifying the moral foundations of fictional characters
1
2
3
…
22
23
Next