
Weird Idea Wednesday: Are sentences like shopping carts?
I’ve decided to introduce a new series to our lab. It’s called Weird Idea Wednesday and the idea is to throw out something a little whacky but potentially interesting. Our field is in its infancy and there is no road map. Weird ideas have an important role to play, even if they help profile the good ideas more clearly. (Some may remember I created a blog called The Bad Ideas blog, so this is something of a recurring theme. Turns out it was a bad idea.)
So this week’s weird idea is what happens if you use the “market basket approach” to studying transactional data and apply it to novels?
Market-basket approaches are designed to identify hidden patterns in people’s shopping habits. It turns out that when you buy milk you also buy eggs (or diapers and beer, the classic example — Dads!). This kind of information can help retailers with item shelving, stocking, or sale bundles. (I’m still waiting for the Molson to be shelved in the baby aisle. Cross-fingers.)
The way it works in practice is every row in a matrix is a “transaction” and the items are columns. You then search for higher than normal co-occurrences. Given the number of times anyone bought beer, what are the number of times they bought diapers (and vice versa)? The more they occur together the stronger the signal (the “lift” in market basket lingo).
My weird idea was to treat each sentence like a transaction and see which words are more likely to occur together. It feels a little like topic modeling at the sentence level, though not quite the same because there are no assumptions about the number of “rules”. Anyway, below I present two tables of the results. I ran it on a corpus of 100 Young Adult Novels, and used the openNLP package in R to divide them into sentences (about 650,000) and remove stop words and duplicates (The idea is it doesn’t matter how many beers you bought when you bought diapers, though this does seem important, both for the child and the sentence.)
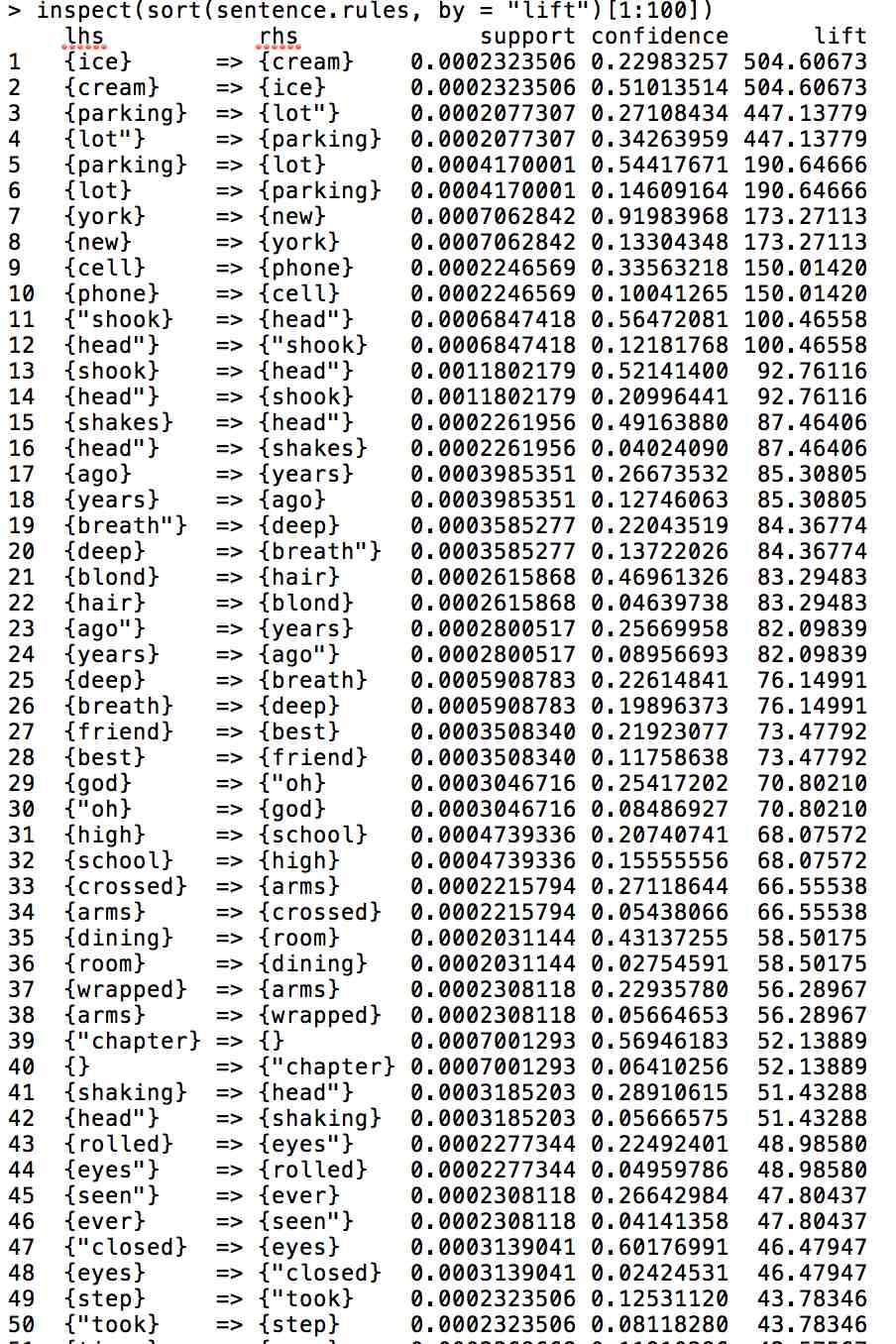
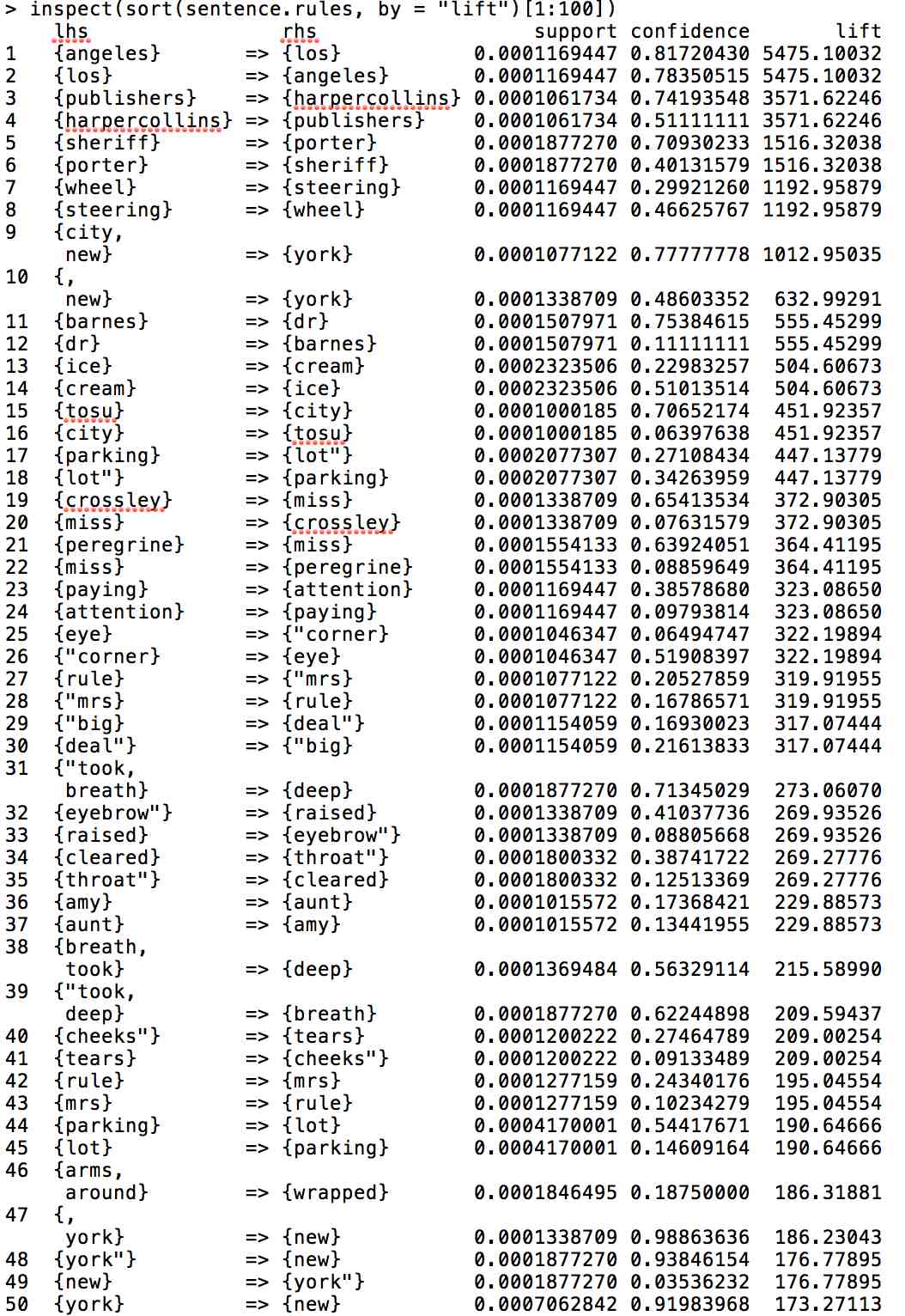
The values are directed, so the first word determines the likelihood of the second. Support = the percentage of sentences in the corpus in which one of these words is present and lift = the increased likelihood of finding them together.
For the most part you get a lot of bigrams: ice-cream, parking lot, new york, cell phone, years ago, oh god, that sort of thing. The further down the list you go, you start to get the equivalent of skip bi-grams (closed [his] eyes, took [a] step). The second list, which has a lower threshold of being present in the corpus finds things like “tears” and “cheeks,” which are probably grammatically further apart (“tears rolled down his cheeks”).
Needless to say, this seems like a lot of very uninteresting information. No secret buying habits of authors suddenly pop into view (parking and lots!! Eureka!).
On the other hand, I was thinking that maybe this could be used as a cliché filter or novelty detector. How many “rules” are accounted for in your sentences and where are they on the scale of likelihood. The more often you talk about parking lots or things being seen out of the corner of someone’s eye, the more we know this is a cliché. Sometimes you can’t avoid it, but the more often it happens could be a sign that an author’s writing (or your writing if you’re an aspiring novelist) needs work. Or maybe clichés are important, especially to highly formulaic genres like YA fiction and bestsellers. Maybe being too original isn’t a good idea at all. Maybe there’s a study in there after all.
Or maybe it’s just Wednesday.
Example 1 (Tighter Filter)
Example 2 (Looser Filter)
1 Comment
Join the discussion and tell us your opinion.
[…] go on!2 I’ve decided to take inspiration from Andrew Piper, who recently introduced “Weird Idea Wednesday” with this astute observation: “Our field is in its infancy and there is no road map. […]