
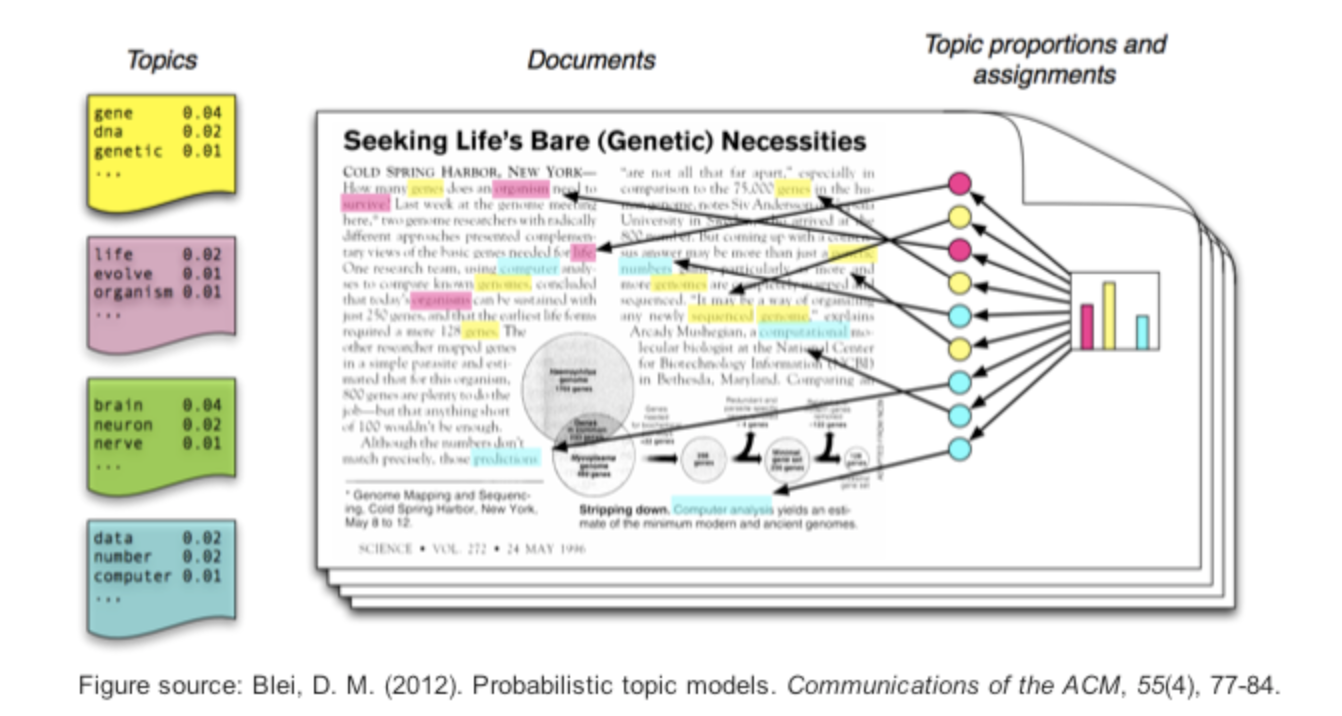
All about topic modeling
For the latest instalment of the Fish and the Painting I have been wrestling with topic modeling. I say wrestling not because the coding is hard but because the analytical value of topic modeling is so hard.
Topic modeling has become a kind of go-to bread-and-butter apple-pie kind of data analytical move. Lots has been written about it. Lots has been written using it. After spending a fair amount of time writing it up to teach other people how to use it I increasingly end up being very cautious and skeptical about its analytical value.
Let me clarify.
I think topic modeling as a dimensionality reduction technique is great. Representing your data in far fewer dimensions that thousands of words can help the problem of overfitting and make your model more generalizable. That’s great.
Topic modeling as an analytical tool, however, is more fraught for me. This happens when a research chooses a single topic to test for its behaviour among different types of documents. Because “topics” are a) rough heuristics we use to designate a vector of word probabilities and b) can fluctuate from model to model with significant differences (more on significance), I am not totally sure what kind of analytical value testing topics can give us.
On the other hand (a data scientists without 2 hands is like the proverbial economist: mute), it is often the case that when run well topics capture semantic objects human readers feel comfortable thinking of as topics and that the differential behaviour of those topics, whether over time or across different communities/classes of writers, can tell us something about people’s behaviour.
Which is all to say, like all methods, topic modeling seems like something that has to be used carefully, with transparency, and the results have to be expressed as cautiously and tentatively as possible because they are contingent upon a host of factors.
This goes for everything with respect to data-driven text analysis, but it feels especially true with topic modeling. Topic modeling is easy to implement, intuitively intelligible, and often provides discriminatory information, i.e. indicates behavioural differences among groups. This is its allure and value. However, as we interpret and UNDERSTAND them, it is important to take account of the contingencies of what we are seeing and ideally run alternative models that can provide alternative explanations to show just how flexible they are.
You can read more at the Fish and the Painting here.