
Let’s talk about debiasing books
This March I will be giving a talk at BookNet Canada’s TechForum. The topic is “debiasing” books and I’ve posted a short blog post to get the conversation started.
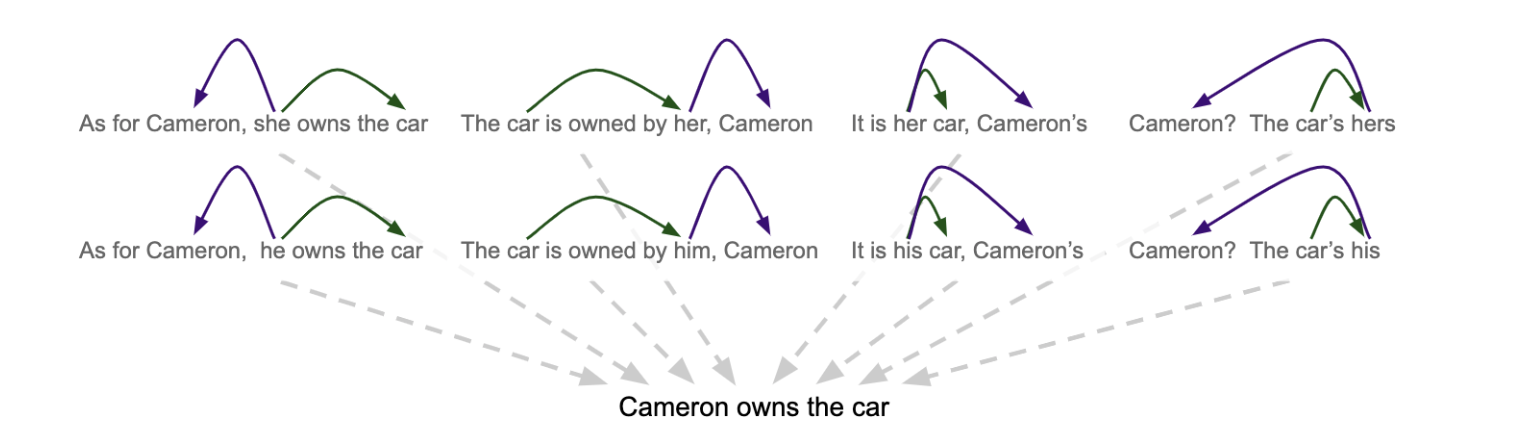
Discussions of bias, and cultural bias in particular, have been much in the air lately. A variety of movements and efforts have emerged to shed light on the deeply imbalanced ways that humans make choices and then amplify those choices through algorithms that they create. The latest one I saw was on how NLP algorithms don’t think women can own cars. That was a good one.
Rather than focus on the bias of algorithms, my talk will explore the ways we can we use data and algorithms to undo the biases that may surround choices humans make as cultural gatekeepers (whether this means you are an editor, publisher, or member of a faculty hiring committee). Data can be a very effective tool for surfacing these biases and providing corrective nudges.
The idea here is to build tools that key stakeholders can use to undo the subtle (or not so subtle) biases in the world of arts and ideas so that those same biases don’t then reappear, magnified, when we automate certain tasks (like predicting grammatical dependencies like who can own a car).
While there are a host of technical issues involved, the more interesting issues to me are philosophical. Is this something authors, editors, and publishers should be doing? How can it be done in a way that feels constructive rather than constraining? If culture is already highly engineered, is such cultural engineering a natural next step (or a slippery slope)?
For me that’s where the conversation starts.