Home
About
Publications
Data Sets
Home
About
Publications
Data Sets
Tag /
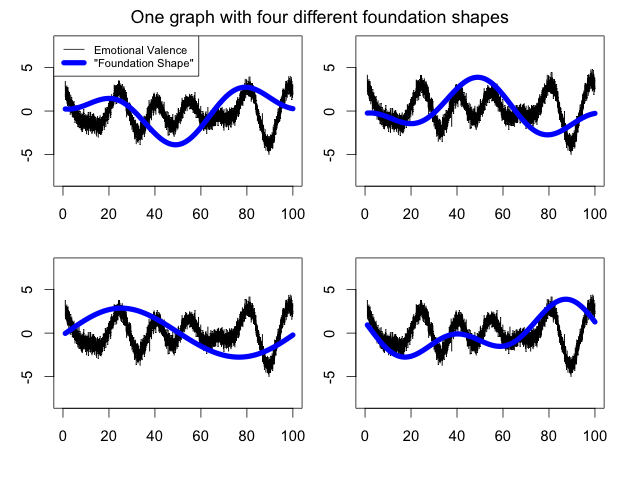
Plot Modelling
Loading posts...
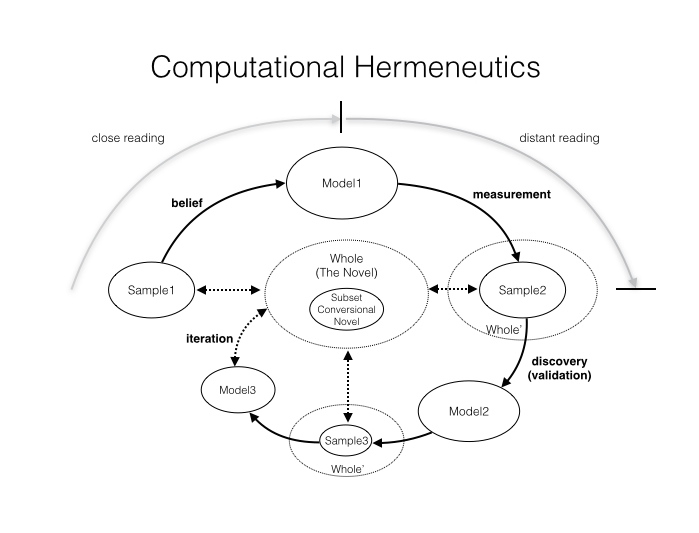
Validation and Subjective Computing
Modelling Plot: On the “conversional novel”