
Validation and Subjective Computing
Like many others I have been following the debate between Matthew Jockers and Annie Swafford regarding the new syuzhet R package created by Jockers, which has been given a very nice storified version by Eileen Clancy. As others have pointed out, the best part of the exchange has been the civility and depth of replies, a rare thing online these days.
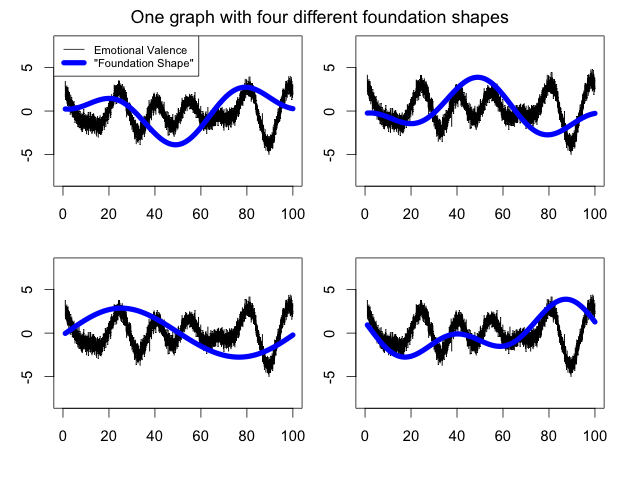
To me, what the debate has raised more than anything else is the question of validation and its role within the digital humanities. Validation is not a process that humanists are familiar with or trained in. We don’t validate a procedure; we just read until we think we have enough evidence to convince someone of something. But as Swafford has pointed out, right now we don’t have enough evidence to validate or — and this is a key point — invalidate Jockers’ findings. It’s not enough to say that sentiment analysis fails on this or that example or the smoothing effect no longer adequately captures the underlying data. One has to be able to show at what point the local errors of sentiment detection impact the global representation of a particular novel or when the discrepancy between the transformed curve and the data points it is meant to represent (goodness of fit) is no longer legitimate, when it passes from “ok” to “wrong,” and how one would go about justifying that threshold. Finally, one would have to show how these local errors then impact the larger classification of the 6 basic plot types.
As these points should hopefully indicate, and they have been duly addressed by both Jockers and Swafford, what is really at stake is not just validation per se, but how to validate something that is inherently subjective. How do we know when a curve is “wrong”? Readers will not universally agree on the sentiment of a sentence, let alone more global estimates of sentimental trajectories in a novel. Plot arcs are not real things. They are constructions or beliefs about the directionality of fortune in a narrative. The extent to which readers disagree is however something that can and increasingly must be studied, so that it can be included in our models. As we’ve recently undertaken here at .txtLAB, in order to study social networks in literature we decided to study the extent to which readers agree on basic narrative units within stories, like characters, relationships, and interactions. It has been breathtaking to see just how much disagreement there is (you’d never guess that readers do not agree on how many characters there are in 3 Little Pigs — and it’s in the title). Before we extract something as subjectively constructed as a social network or a plot, we need to know the correlations between our algorithms and ourselves. Do computers fail most when readers do, too?
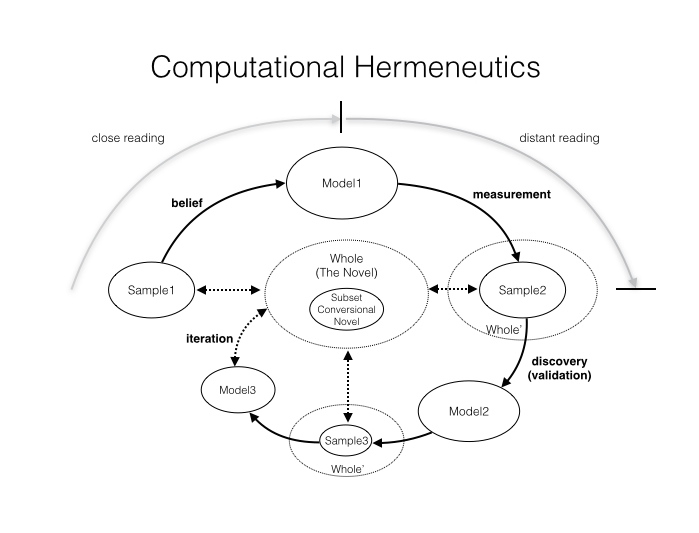
What I’m suggesting is that while validation has a role to play, we need a particularly humanistic form of it. As I’ve written elsewhere on conversional plots in novels, validation should serve as a form of discovery, not confirmation of previously held beliefs (see the figure below). Rather than start with some pre-made estimates of plot arcs, we should be asking what do these representations tell us about the underlying novels? Which novels have the worst fit according to the data? Which ones have the worst fit according to readers? How can this knowledge be built into the analytical process in a feedback loop rather than a single, definitive statement? How can we build perspective into our exercises of validating algorithms?
While I don’t have any clear answers right now, I know this is something imperative for our field. We can’t import the standard model of validation from computer science because we start from the fundamental premise that our objects of study are inherently unstable and dissensual. But we also need some sort of process to arrive at interpretive consensus about the validity of our analysis. We can’t not validate either.
The debate between Jockers and Swafford is an excellent case in point where (in)validation isn’t possible yet. We have the novel data, but not the reader data. Right now DH is all texts, but not enough perspectives.
Here’s a suggestion: build a public platform for precisely these subjective validation exercises. It would be a way of basing our field on new principles of readerly consensus rather than individual genius. I think that’s exciting.
5 Comments
Join the discussion and tell us your opinion.
[…] Right now DH is all texts, but not enough perspectives. -Andrew Piper […]
[…] proved the success of his tool. This blog post will respond to that claim as well as to recent comments by Andrew Piper on questions of how we validate data in the […]
[…] of discussion around Matt Jockers’ Syuzhet package (involving Annie Swafford, Ted Underwood, Andrew Piper, Scott Weingart and many others) has focused on issues of validity — whether sentiment […]
[…] interest after the recent Syuzhet conversation, and I think the kinds of collective validation that Andrew Piper and others have called for would be made vastly easier by a somewhat standardized set of model […]
[…] of algorithms and how they relate to the specific questions asked. Andrew Piper’s blog post, “Validation and Subjective Computing” also speaks to how work in the digital humanities needs to be analyzed across perspectives, […]