
Prizewinners versus Bestsellers. Timeless Reads or the Spotlight of Fame
This post is the first in a series by this year’s .txtLAB interns. It is authored by Eva Portelance.
Building Corpuses
The first step in our search for answers required that we build solid corpuses for comparison. The PW corpus was selected from five main literary awards given in the United-States, Canada and Britain. These were the National Book Awards, the PEN/Faulkner Award for Fiction, the Governor General Literary Award for Fiction, the Scotiabank Giller Prize and The Man Booker Prize, this last one also awards international authors who have been published in the United Kingdom. From these awards, all shortlisted books, including the winners, from years 2005 to 2014 that were available as e-publications in Canada were selected. This amounted to 216 books. Publications that had won several prizes were only added once to the set. As for the BS, the 200 most popular books from the New York Times Bestsellers list from 2008 to 2014 were selected. This criteria was defined by the number of weeks spent on the list. The additional criteria that the novels had to have been published post- 2000 was also considered to try to better match the publication dates of the PW.
Defining Dictionaries
The corpuses created, we began testing different avenues in search of clues that could help us create a clearer picture of what it was that made these groups distinct within their shared fictionality. The two sets were rather similar, but the most interesting differences seemed to lie in their distinct lexicons, suggesting different themes and approach to written work in general. To illustrate these differences, dictionaries highlighting these themes and behaviours were selected. The process which led to their creation was thorough and avoided subjective criteria as best possible to ensure their validity. First, we ran a likelihood test which creates a matrix of common words to a first set, that is, words that seem to be present throughout the corpus and thus, possibly representative of the set. This matrix is then cross-referenced with a second set to only look at words which are present in both corpuses and uses a Wilcoxon Rank Sum test to rank and select the 400 most distinctive words, which in turn are likely to be indicative of characteristics of the first set. We ran the test in both directions thereby creating a dictionary representing each of the corpuses. It is important to note that the sets were both ridded of stop words and stemmed, so not to be surprised by the unconventional orthography or lack of inflection on the resulting dictionaries presented in the graphs bellow. The words used for the subsequent dictionaries investigating theme and language use were selected from these two resulting lists.
Timelessness and Momentary
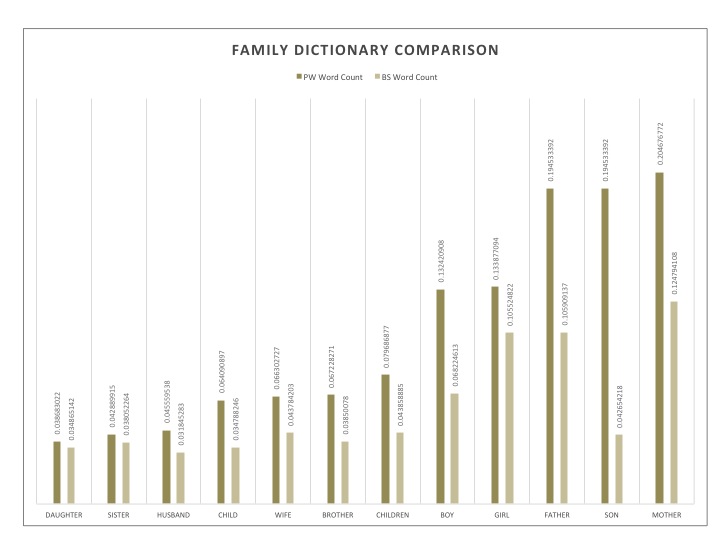
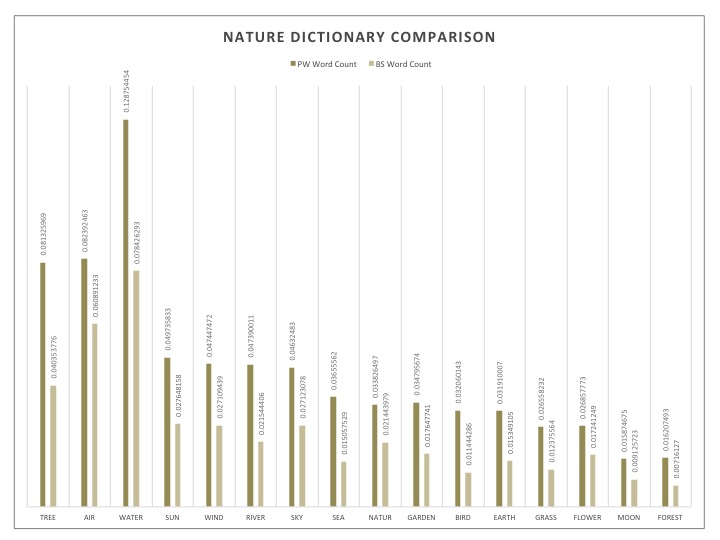
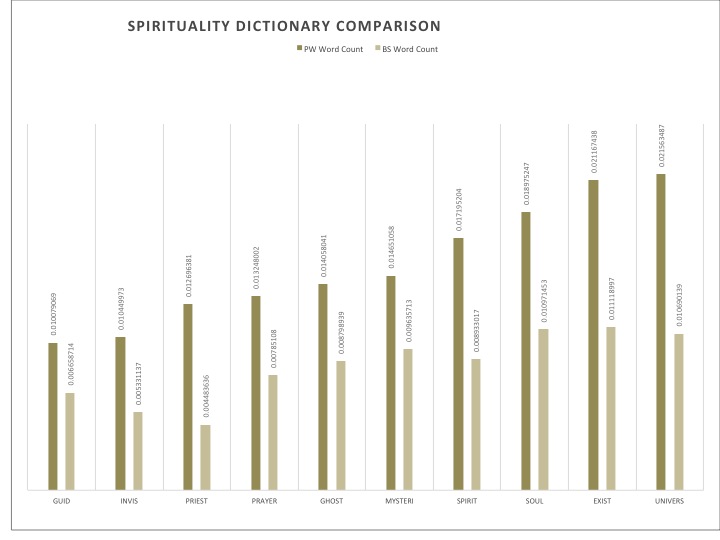
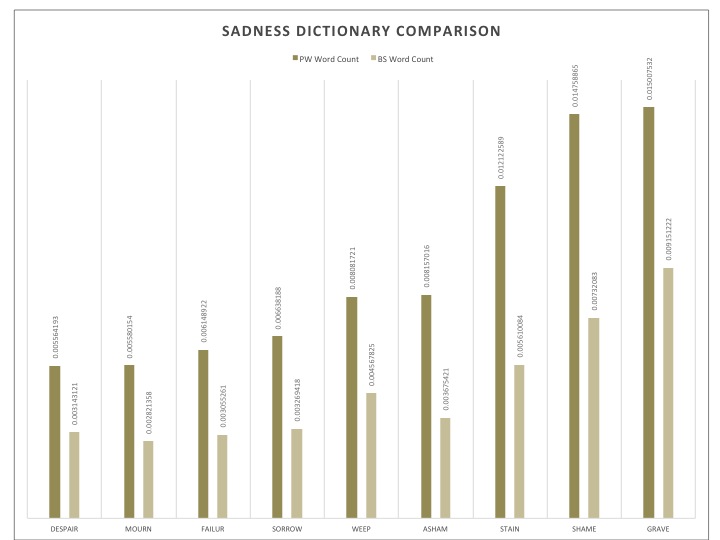
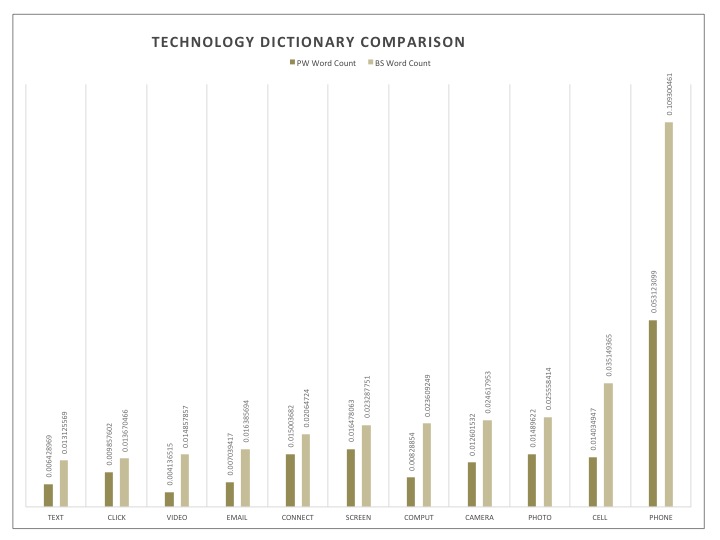
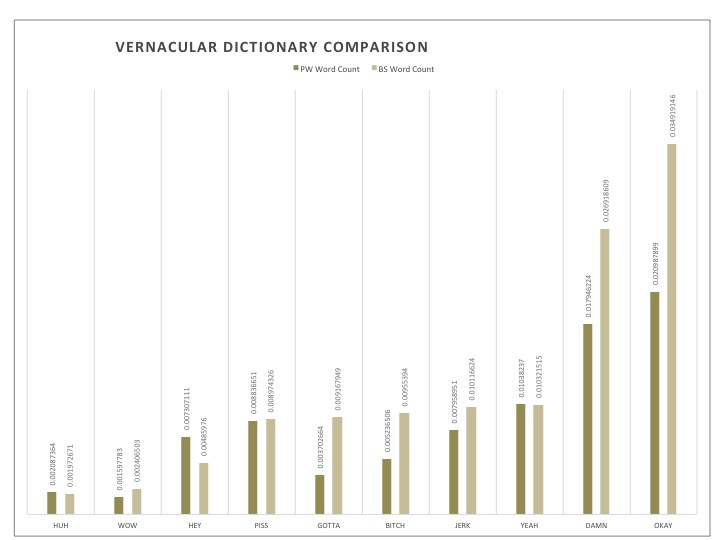
Recurring themes for the PW corpus seemed to be family, nature as well as sadness and spirituality: the key components of a good soul searching endeavor. This concentration on nature also suggested the importance of descriptive passages. As for BS, interesting sets of words that were explored were technology related words and vernacular words. What peeked my curiosity was the most however was not necessarily the distinct themes themselves, but rather the distinctive words used within similar categories. The example I will share here is that of time. PW seemed to use words that spoke of time in terms of visual cues or spatial relations, referencing the age of characters, or seasons, whereas the BS had words that were based on the factual nature of time, like “minute”, “hour” or “yesterday”. With this in mind, I found that the other key categories mentioned for PW could also be looked at in this light, seeking universal and timeless values such as family and spirituality, no matter if they be discussed in a positive or negative light. Those mentioned for BS speak of things in passing, technology and popular speech are always evolving and certainly do not represent language or ideas that are expected to withstand time, often expiring even within a few years. These are things that readers will understand and breathe in the moment. To this extent, they propose a very different relation to time than do the writings in the PW corpus. They speak of momentary ideas and if this also applies to their storylines, it would suggests events of ephemeral pleasure or pain, rather than contemplation.
Language and Thought
To generalise this idea even further, I question whether the use of language in PW and BS is indicative of different intuitions on language, but also on the world it chooses describe. Whether something is well written if often highly based on prescriptive ruling and thus, there is less interest in knowing what makes a good book. However, what is chosen to be written about and the perspective used to do so is anchored in descriptive thought processing. Therefore, I center my attention for further reflection on a new question: Is the language used by the authors of these books from two distinct sets indicative of a shared thought process or perspective of writing, or even the world they choose to describe?
List of Graphs
Here are bar graphs representing each dictionary mentioned. The dictionaries were originally a little longer, but the most indicative words were selected here. This selection was based on the sparsity level of a word through its most representative corpus. The data presented compares the scaled word count of a specific variable throughout the sets.
3 Comments
Join the discussion and tell us your opinion.
[…] Portelance, “Prizewinners versus Bestsellers,”.txtLAB, blog. (18 May […]
[…] Eva Portelance, “Prizewinners versus Bestsellers.” txtLAB, 18 May […]
[…] that I could have been doing infographics, like what we read about in the Andrew Piper article over Prizewinners versus Bestsellers, for the store during my time there. I would say the downside would be that in order to access all […]