Home
About
Publications
Data Sets
Home
About
Publications
Data Sets
Tag /
prizewinners
Loading posts...
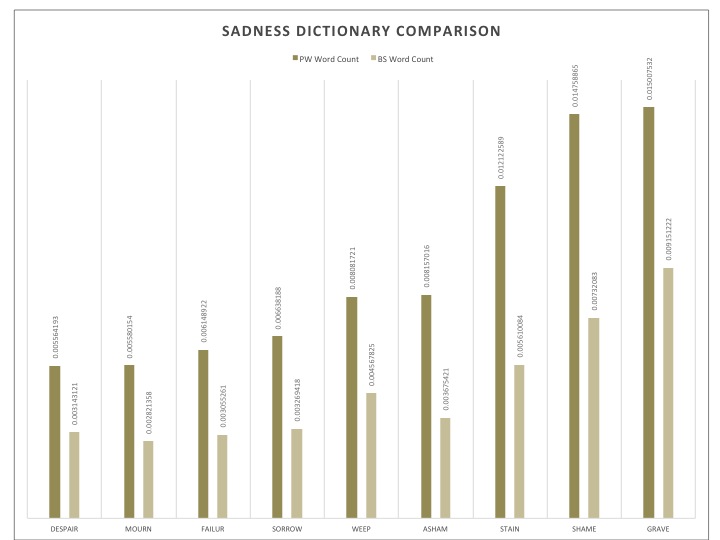
How Cultural Capital Works: Prizewinning Novels, Bestsellers, and the Time of Reading
How I predicted the Giller Prize (and still lost the challenge)
Can a computer predict a literary prize?
Prizewinners versus Bestsellers. Timeless Reads or the Spotlight of Fame