Home
About
Publications
Data Sets
Home
About
Publications
Data Sets
Tag /
Novel
Loading posts...
What do novels teach us? Using AI to trace the moral history of the novel
Computational Narrative Understanding: The Big Picture
Modeling Narrative Revelation
Are you into thing theory?
The End of an Era. NovelTM celebrates its final workshop, “Ends”
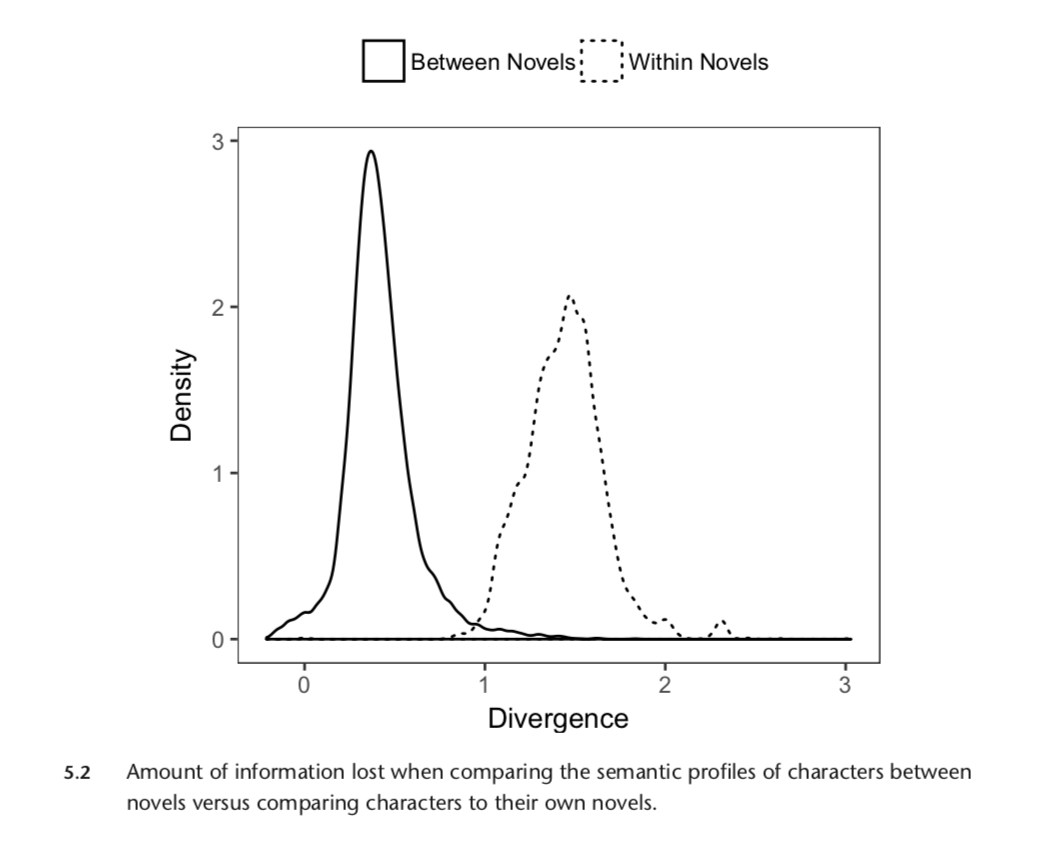
Are characters really all that special?
LIWC for Literature: Releasing Data on 25,000 Documents
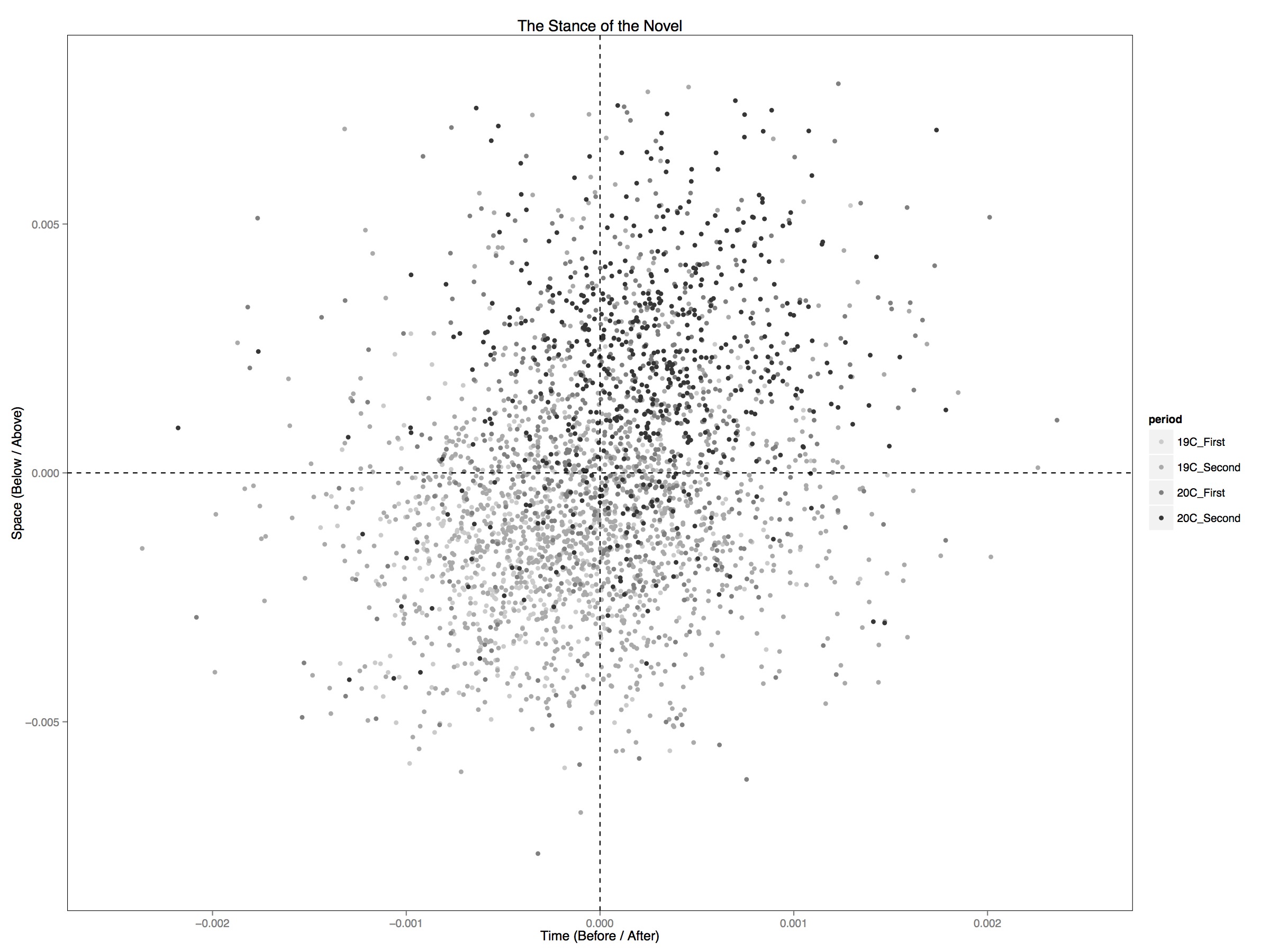
Upward Looking and Forward Thinking? The Stance of the Modern Novel
1
2
3
Next