
Topic Modelling Literary Studies: Topic Stability, Part 1
I’ve started working with a new data set of ca. 60,000 articles from the field of literary studies published between 1950 and 2010 courtesy of JSTOR. I’ll have more to say about the data set in the coming weeks, but for now I want to dive into a discussion about topic modelling this corpus.
Part of the aim is to do what is called a conceptual replication of Andrew Goldstone and Ted Underwood’s work — does a different data set of the same object (literary studies) tell the same story? Part of the aim is to continue my lab’s work of better understanding the disciplinary field of literary studies (here on institutional bias and here on authorial concentration), what I am tentatively calling “metatextual studies.” (It also goes by the name of “the science of science” but that would be squaring the initial problem…) And part of the aim is to continue the work I did in one of the chapters of my new book where I do a deep dive into topic modelling a literary corpus.
If I had to summarize, I would say that there are three basic challenges when topic modelling a corpus:
- topic number — how to choose the best number of topics (“k”)
- topic coherence — how to understand what is inside a topic
- topic stability — how to to understand how stable a topic is across multiple models of the same k
A lot of discussion around topic modelling revolves around #1, as in how many topics do you choose. Reviewing the literature, this is often boiled down to “domain expertise.” I know this data set and I feel this number of topics is the best representation. I find that a frustrating answer when I observe how different the topics are at different levels of k. What I think I see happening is a process of decreasing generality as certain topics splinter into more specific versions of themselves. But I’m not sure how to link that a) to a theory of “topics” and b) to some sort of replicable process (i.e. quantitative).
In my book I do a deep dive into #2. How might we understand the coherence of a topic and what kinds of “subtopics” or “cotopics” might it contain? I provide some exploratory methods on how to do this there. One of the basic measurements for this is David Mimno’s et al.
For this post I’m going to focus on #3: what happens when you run multiple models at the same k but use different seeds? As practitioners know, you always get slightly different topics. So far I don’t know of any literature that investigates that “slightly.” If you know of some, please email me.
I should say at the outset that topic modelling seems very appropriate for this kind of corpus. After running initial models (and cleaning my words, again and again and again) I saw very coherent, well differentiated topics at the 50 and 60 topic level. As a “domain expert” I have some confidence that these vocabulary distributions meaningfully correlate with my own understanding of important topics in the field. Academic articles feel “topical” in that they are oriented around clusters of terms or concepts so that modelling them in this way makes sense to me (potentially less true for literary texts, but TBDebated).
Since choosing a single model based on a single k is at this point still ultimately arbitrary my goal here is to better understand the stakes of the variability that exists between different runs at the same k. My assumption is that as you increase your k, the overall variability between runs should increase. Your topics will be more specific and thus subject to more randomness depending on the starting point. That’s probably not that informative.
But if you want to zoom in and talk about a specific topic, this variability seems important to discuss.
Take a look at this example to see why I think this matters so much (and of course maybe it doesn’t):
| Topic 21 |
| cultural |
| culture |
| identity |
| social |
| discourse |
| political |
| within |
| power |
| politics |
| studies |
| community |
| practices |
| ways |
| self |
| forms |
| practice |
| terms |
| rather |
| difference |
| critical |
If asked, I would label this topic the “cultural studies” topic (for fairly obvious reasons). It seems to be about questions of social discourse as well as identity politics, both associated with the cultural turn. If you examine when this topic becomes prominent, the timeline also makes sense:
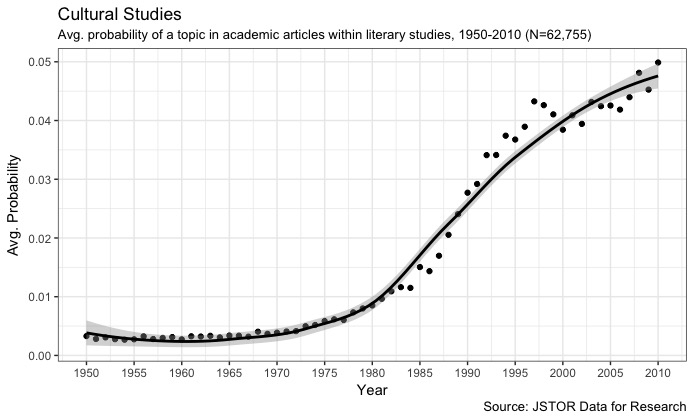
But notice how in the second run this topic has a very different semantic orientation.
| Topic 44 |
| cultural |
| culture |
| identity |
| national |
| studies |
| chinese |
| world |
| cultures |
| western |
| global |
| ethnic |
| within |
| community |
| nation |
| japanese |
| china |
| practices |
| different |
| states |
| american |
Instead of being about culture, discourse, and identity, it appears to be more about culture in the sense of national communities. The temporal signature is roughly the same (a few years later, a less strong weight overall). But I now have at my disposal two different narratives about disciplinary change — one hinges on an idea of cultural studies as a more general project concerned with discourse, power and identity, while the other appears to be concerned with different national identities.
Here is a list of the top 10 journals associated with these two versions:
| Model1 | Model2 |
| Cultural Critique | The Journal of American Folklore |
| Signs | boundary 2 |
| Social Text | Social Text |
| boundary 2 | Cultural Critique |
| American Literary History | Signs |
| The Journal of American Folklore | American Literary History |
| Studies in American Indian Literatures | Studies in American Indian Literatures |
| Victorian Studies | Caribbean Quarterly |
| PMLA | Feminist Studies |
| Diacritics | Comparative Literature Studies |
Here we see how the nationalism model favours journals like Folklore, Caribbean Quarterly, American Indian Literatures, and Comparative Literature versus PMLA, Diacritics, and Victorian Studies.
If we look at word clouds of the titles of the top 50 articles associated with this topic we see pretty difference emphases.


I guess the larger point is that these topics are very much related, but not identical. They emphasize different aspects of cultural studies. For very general questions like “when does this topic gain in currency” this won’t matter much. But if you are going to tell a story about “cultural studies” then it matters which version of cultural studies one looks at and also how stable that definition is.
In Part II of this post I will look at some ideas for how to get a handle on this variability and what could be done about it. I’m also very willing to be convinced that this problem is impossible to make go away because all topics have different “aspects” and so any generalization will activate these aspects in different ways. Having recourse to the contents of the topic make this more interpretable and might be all that we need.
Thanks to Richard Jean So, Jo Guldi, and Simon DeDeo for helping me think through these ideas.
1 Comment
Join the discussion and tell us your opinion.
[…] my previous post I tried to illustrate how different runs of the same topic modelling process can produce topics […]