
Are characters really all that special?
Browsing through the history of literature, you are likely to find authors poking fun at their characters for just being words on the page. As George Eliot writes in Middlemarch, “‘He has got no good red blood in his body,’ said Sir James. ‘No somebody put a drop under a magnifying glass, and it was all semicolons and parentheses,’ said Mrs Cadwallader.” Authors are acutely aware that their characters-as-people are nothing more than characters-as-type.
On the other hand, if you browse through readers’ responses to literature you will find a lot of swooning over characters. Characters occupy a lot of our focus and attention when we read (for obvious reasons).
All of this raises an interesting research question: how are characters distinctively signalled by authors to produce such reader responses? What makes characters so special?
To try to understand this idea of the distinctiveness of literary characters — how they stand out in the texts in which they appear — I undertook the following set of experiments (all outlined in Chapter 5 of Enumerations). To understand the relative strength of the semantic distinctiveness of characters, I first treat characters as a “vocabulary distribution” of dependent words. What this means in practice is that I first identify a character’s location in a text, and then accumulate all of the words that stand in a dependent relationship with that character. David Bamman defines four key dimensions of a character’s semantic identity:
- What characters do.
- What characters have done to them.
- How characters are modified.
- What characters possess.
Bamman’s schema gives us a nice model for capturing what I call “the character text” of a novel — all of the words associated with characters (not including dialogue, which I would treat as its own text-within-a-text).
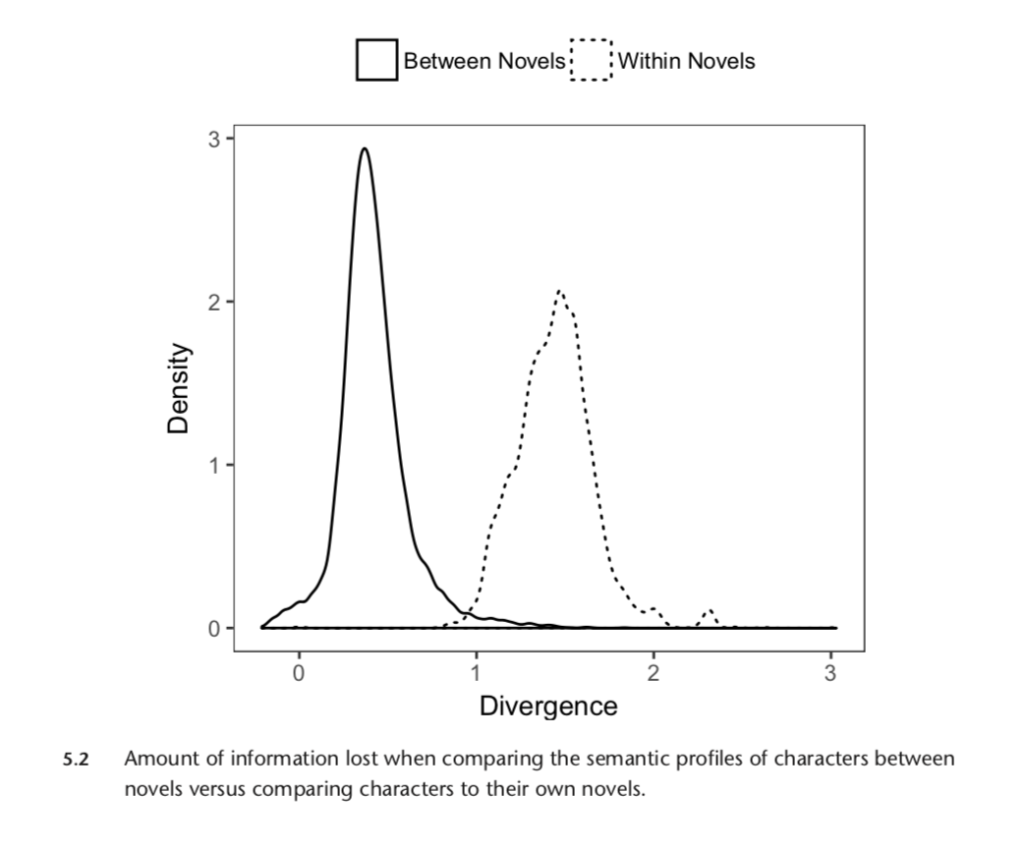
Once I have these representations of characters, I then proceed to test how informationally rich characters are, using two methods. The first is to use machine learning, where I compare the predictability of a text first using all the words of a novel and then again using only words associated with characters and words not associated with characters. As the following table shows, we see no decrease in predictive accuracy when we compare models without characters and models with only characters. In other words, if you read a novel without characters, you could tell its genre as well as if you read the same novel with only characters. Characters do not appear to contain any additional knowledge about the kind of text you’re reading.
I found this a very surprising insight about the nature of literary character.
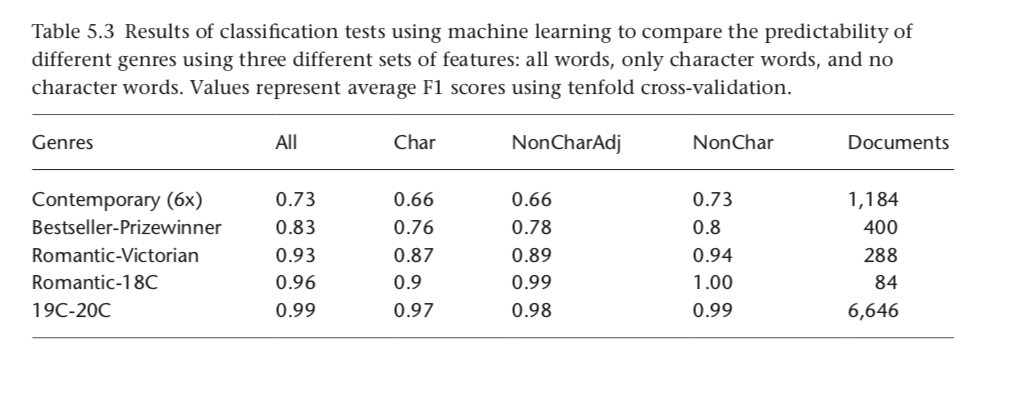
The second test I ran is to compare the semantic similarity of characters between novels and compare that level to the semantic similarity between characters and the novels they come from. Are characters more similar to their works or to other characters from completely different works? Here, the results are even stronger. In the following figure you see the rates of Kullback-Leibler Divergence (KLD) for random sets of characters when compared either to other characters from other novels or the novels from which they come. KLD captures how much information is lost when we approximate one probability distribution by another. In our case this means the higher the number the more surprising the one distribution looks from the perspective of the other. Below you see how approximating characters by other novels’ characters is way less surprising than approximating characters by the language of the novels they come from.
Again, this really caught me by surprise. I assumed that characters would bear a fair amount of a novelist’s signature and certain plot points would just make them look like the worlds from which they derive. But it is quite the opposite. Characters are much more similar to other characters from totally distinct worlds (I did keep the genre constant however, so mysteries are compared to mysteries, etc).
I then went on to test a bunch of other possible scenarios. Characters are also more similar to each other in the same novel than other nouns are to each other from the same novel. There is more semantic homogeneity surrounding the practice of characterization than other kinds of nouns in novels. Even if we do this over time, nouns are more distinctive — if we compare the semantic framing of common nouns in novels to themselves in the first and second halves of a novel there is more dissimilarity than for characters. While we think of characters “changing” or “evolving” this is not semantically the case compared to other nouns like “tree” or “apple.”
All of this puts pressure on the idea of the specialness of character. And yet of course we know as readers that characters are special. We really care about them! What I think these findings gesture towards are two future directions of research: a) thinking more about the role of dialogue for grounding characters’ distinctiveness; and b) thinking about the role the reader plays in imagining these differences. How much is occurring on the page and how much am I as reader enlivening these figures of speech? I suspect humans have a very powerful personification engine in their brains that does a lot of the work that language isn’t doing here. But that is, as they say, a question for future research.