

How can we understand characters using data?
So for my first post, I want to discuss techniques that you can use to find and understand “characters” in literary texts. The tool I will be discussing is called BookNLP and is developed by David Bamman at UC Berkeley. It is a wonderful resource that pulls together a number of different functions including:
- tokenization
- sentence boundary identification
- part of speech tagging
- dependency parsing
- entity recognition
- entity mapping (aligning aliases to a single character ID)
- gender prediction
With this tool you can undertake a number of different types of projects. For example, you can model the distribution of gender across characters as Eve Kraicer and I have recently done (forthcoming in the Journal of Cultural Analytics).
Or you can try to understand the semantic identities associated either with individual characters or character types (heroes of Sentimental Novels or Science Fiction, men and women, characters whose names start with J, etc.).
While there are an endless number of questions you can ask, and I’ll be discussing some in subsequent posts, for now I want to look under the hood to see how the data annotation works and how the outputs look so you can have a better idea of what you can do with them.
Step 1: Tokenization
“Tokenization” refers to the process of splitting text up by words (“tokens”). Tokens don’t have to be words (they could be letters for example) but words are the most intuitive unit in a text. We refer to “types” as categories of tokens (for example, an instance of the word “tree” is a token, while the word tree itself is a “type” — every time the word tree occurs, these are tokens of the type “tree.” Tokens = instances, types = categories.) You might be familiar with the measure called type/token ratio which measures the rate at which you repeat yourself (also known as vocabulary richness).
Anyway, tokenization allows us to see every word as its own row in a table, which we will gradually “enrich” with more information.
Step 2: Sentence boundaries
Sentences are important grammatical structures. Words that are in the same sentence have a relationship that words across sentences do not necessarily have. Research question: what is the cross-sentence relationship between words and how is this a function of distance, i.e. the further away you get are words less “related” in some sense?
For now, we’re going to treat relationships between words as *within-sentence* relationships. Sentences are not obvious to parse, so BookNLP relies on a model to make educated guesses, which means not all of its annotations are going to be correct. This is true of just about everything with data science, which means you need to get comfortable with ideas like error and uncertainty. More on that later.
Step 3: Part of speech tagging
Knowing what part-of-speech each word is can allow us to better understand contextual information about that word. Stephen King once said the road to hell is paved with adverbs. Grammatical qualities are important to how we think texts convey meaning. It will also be essential for the next step of “dependency parsing.” For now, what we do here is again make educated guesses on whether a word is a noun, verb, object, adverb, adjective, etc. The Penn Treebank lists 36 types of POS that are used in BookNLP.
Step 4: Dependency Parsing
Linguists think in terms of dependencies between words. The meaning of the subject of a sentence depends in part on the verb of the sentence, just as the object of a sentence stands in a dependent relationship with the subject and the verb. Here is a classic image of the dependency structure of a single sentence from the Stanford NLP website:
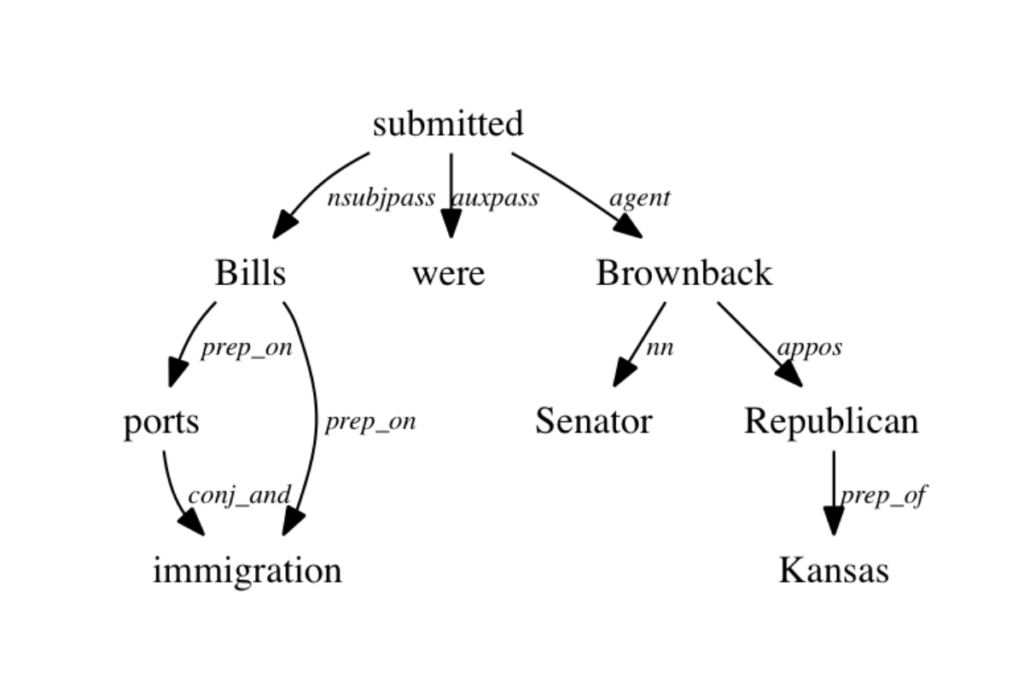
What this allows us to do is identify relationships between words that are grammatically motivated rather than spatially motivated (i.e. words “nearby”). This may not actually be the best assumption if you are trying to model meaningful words. Research question: can you find different types of texts that behave differently with respect to the relationship between words? Are some documents better modelled by dependency relationships and others by more distant proximities (paragraphs, pages, chapters, etc)? Or is it more a matter of the type of question or theory that determines the best model of linguistic relations?
Step 5: Entity Recognition
Ok, almost there. The penultimate step is the identification of people. People are a particular type of “entity” and entities are a particular type of noun. So what we’re doing here is again using models and training data to infer whether a word is an entity and if so if it is a “person.”
Step 6: Entity Mapping
Now that you know which words refer to entities how do you know which ones refer to the same entity? This falls under the heading of co-reference resolution. Whom does “he” refer to when we read the thousands of pronouns in a text? Again, BookNLP makes educated guesses about these resolutions.
And from there you now have all the pieces of enriched information about your words and characters. The output looks like this:
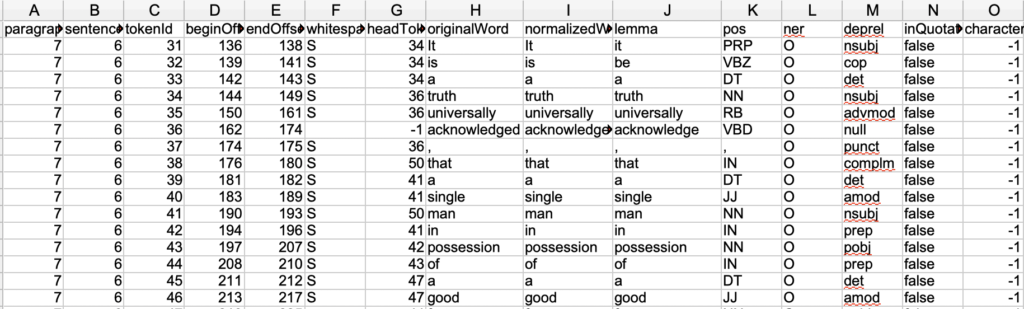
Here you see every word (token) is a row, and these words are marked by sentence boundaries, part of speech, its root form, and its dependency position so you can establish relations between words. Finally, you see a column with a character ID. For now they are all -1, meaning they are not characters. Here is a row with a character:
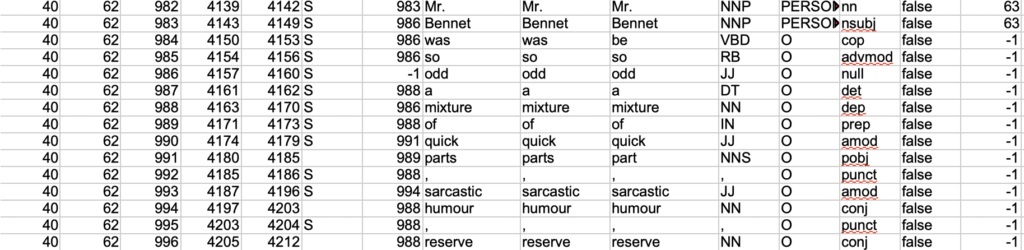
All of this may look intimidating at first. What do all these abbreviations mean!! But you will gradually learn that this is a powerful tool for large-scale text analysis. It allows you to focus on entities and the semantic framing they undergo in numerous texts.
So that’s it (for now). There are so many interesting research questions buried in here already. When does the model get names wrong? Why? Are there consistent errors or random errors? Are characters only people? Should we be modelling “agents” instead, and how would we do so? What does “textual agency” look like?
Just thinking about the conditions of characterness is a great first step before jumping into the analysis of character. But if you’re ready for that, the next post is soon to follow.