
How do disciplines change?
Over the past few years I’ve become interested in better understanding how my own discipline works. As someone whose work has changed considerably over the past decade, it’s probably a predictable response. In one sense, it is about asking, How do I fit in?
On the other hand, I am also following in the footsteps of a growing body of work that aims to study what researchers are calling the “Science of Science” or “metaknowledge” — knowledge about how knowledge is produced. While there are a lot of interesting qualitative histories of our discipline out there, very little work has used new affordances in NLP and machine learning to study the behaviour of our field at larger scale. What have we been saying and doing and how has this changed over time?
One of the reasons I’m interested in the question of time is that I have the impression (unproven) that disciplinary histories either tend to assume some monolithic thing that “has always been this way” or they emphasize sharp pivots or “turns.” Suddenly, everything is different. As Ted Underwood has tirelessly demonstrated, that is a very poor model of how historical change typically works when it comes to language and discourse.
In a new work out, I have teamed-up with my collaborator Stephania Degaetano-Ortlieb to try to model what we call “the scientization of literary study.” The study of literature has historically been seen as a scholarly practice that is distinct from the natural sciences. Literary scholars, and humanists more generally, see themselves through a lens of distinction.
Our aim in this paper is to test the opposing view to this consensus, namely, that literary studies has over the past half-century become more “scientific.” By this we do not mean that literary studies has gradually come to share similar vocabulary or concepts to other scientific disciplines. To be “like science” in this sense does not mean the adoption of a distinctly scientific language. Rather, we define the process of scientization as a set of three interlocking linguistic practices, which we set out to test here:
- Social differentiation. To what extent has the discourse of literary studies become more/less like standard English and how does this compare to a corpus of “scientific” writing?
- Diachronic specialization. To what extent has the discourse of literary studies become more/less dissimilar to itself over time, i.e. evolved a more technical vocabulary that looks less like its past self, once again compared to scientific writing?
- and Phrasal standardization. To what extent has literary studies increasingly employed phrases as a means of standardizing technical or even colloquial jargon? How does this rise compare to the sciences?
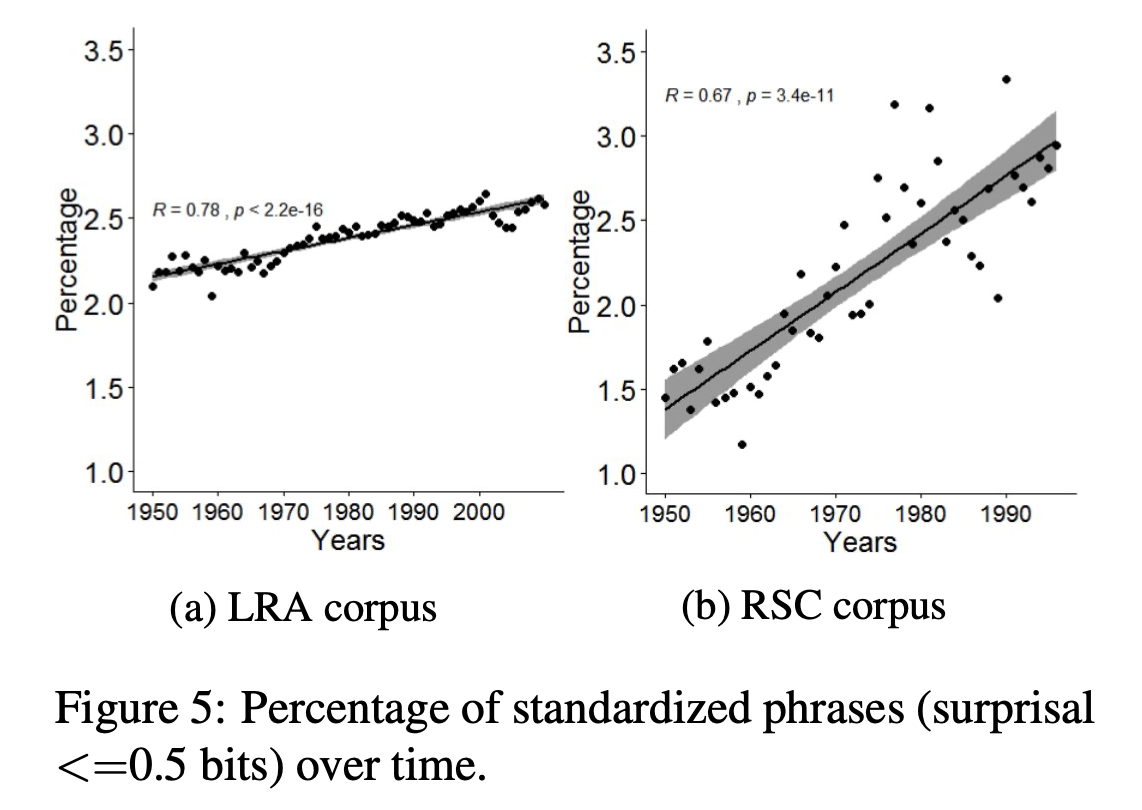
We compare three datasets: a collection of 63,397 academic articles published between 1950 and 2010 drawn from 60 journals within the field of literary studies provided by JSTOR’s data for research service; a collection of the Proceedings and Transactions of the Royal Society of London from 1950 to 1996; and the Corpus of American Historical English for the same time period.
Methodologically, we use the information-theoretic measures of relative entropy (Kullback-Leibler Divergence) and surprisal. Kullback-Leibler Divergence is used to determine diverging trends between corpora/time periods. KLD allows us to approximate how much information is lost when we model one vocabulary distribution by another. For example, how much harder is it to approximate standard English by the language of literary studies than it is to approximate standard English by the language of science? Measured in this way we can see the difference in divergence between different communities’ language use.
For example, we measure the divergence between the literary studies corpus and historical English for different time periods and plot this alongside our science corpus’s relationship to historical English. As we can see, literary studies is consistently closer to standard English than science, but this difference is converging. They are becoming more like each other in their difference from English.
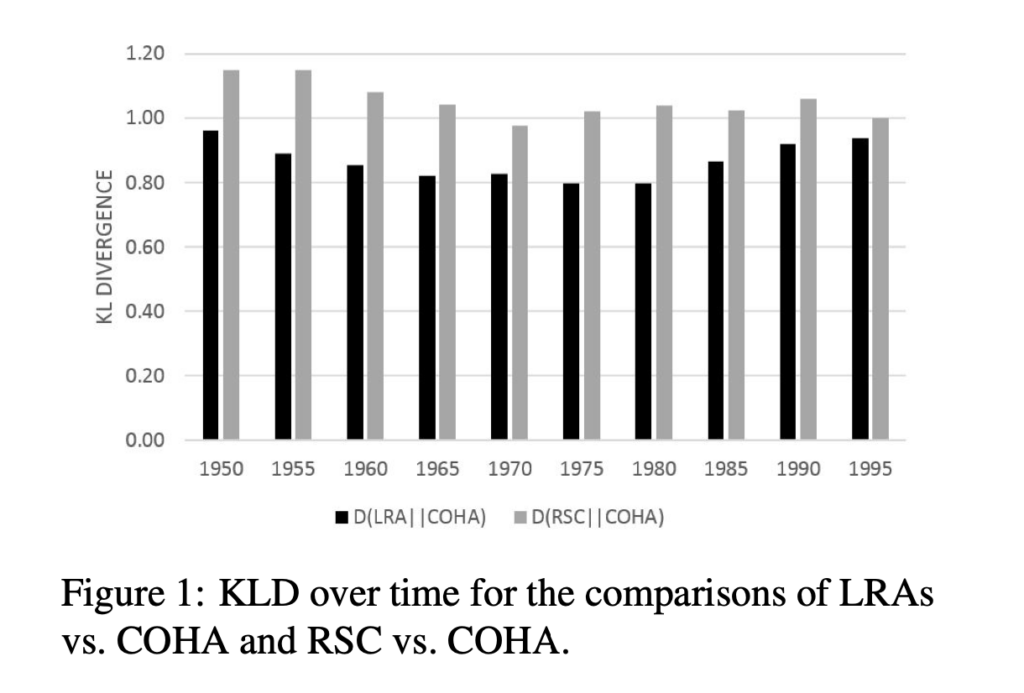
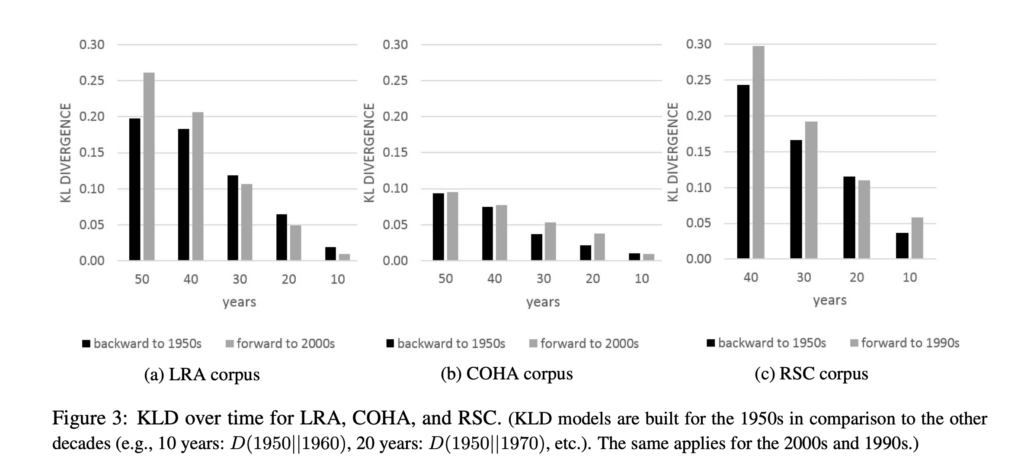
Similarly, we can do the same thing to compare a corpus to itself over time, as well as test divergence in either direction (forwards or backwards). In other words, is literary or scientific language getting harder to understand from the view of the past or is the past harder to understand from the view of the present? The former might indicate a process of specialization, as the literary studies of the present has a new highly technical vocabulary that looks strange from the point of view of the 1950s, while the 1950s vocabulary is still partially active in the present and thus there is less confusion or surprise when looking in this direction.
As we see, the further two time periods are the more divergence or surprise there is, and in general looking forward is more confusing for both science and literary studies than looking backwards. The present looks stranger from the viewpoint of the past than the past looks from the present suggesting that our belief about the development of new technical vocabularies may be well supported. For example, we do not see this directional divergence in the standard English corpus suggesting that there is a consistent drift of language over time (both past and present look equally (and far less) surprising from either vantage point.
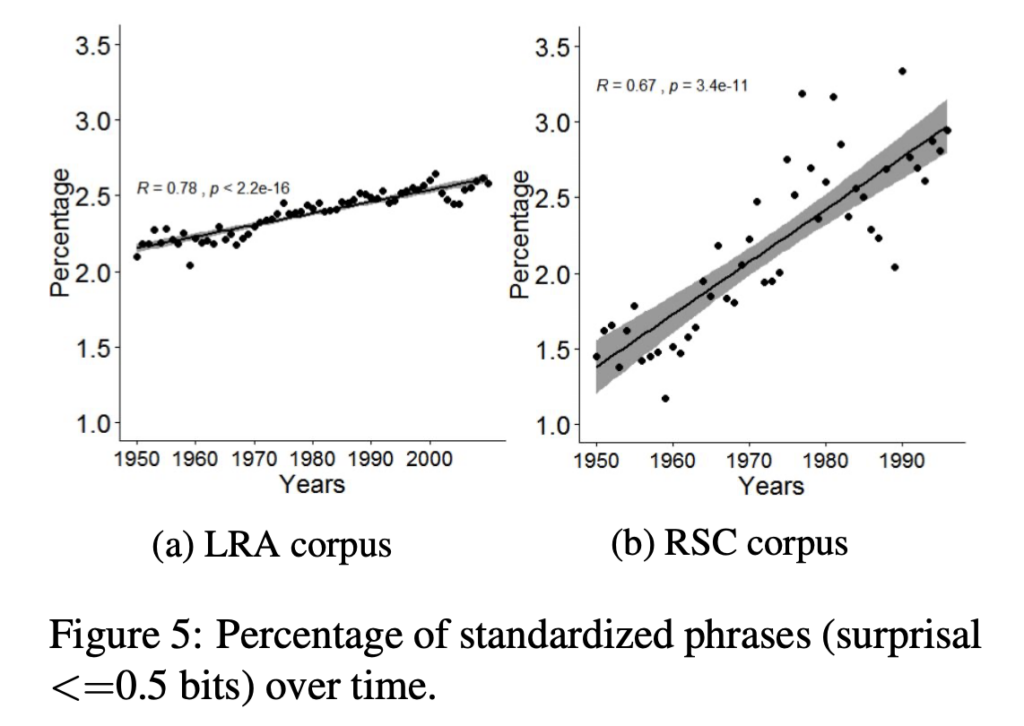
Finally, we measure the degree of surprisal found in documents, which looks at the extent to which expectations about the sequencing of words is violated/followed. Given a context of two words, how surprising is the word that follows? This can be a way of capturing more standardized language use. Phrases with low surprisal are those such as be able to, in order to etc., while those with high surprisal are expressions like high cultural poetics. The figure below looks at the % of phrases that have low surprisal (i.e. < .5 bits), which we expect to represent more standardized expressions. As we can see, both science and literary studies have demonstrated steady increase, with science exhibiting much stronger increase in this area over the past half century.
I wanted to share these methods because they can give researchers new tools for thinking about temporal change when it comes to language use. As we see in all cases, such changes are gradual and often steady. At the same time, there is a great deal of future work to do to calibrate these measurements against human judgments. How many bits correspond to judgments of interpretive difference? When do readers notice/feel a difference by the intensity of KL-divergence?
In the particular case study of whether literary studies should maintain its self-conception as “distinct” from scientific discourse, the answer, as is almost always the case, is: it depends on how you look at it.
1 Comment
Join the discussion and tell us your opinion.
[…] it’s probably a predictable response. In one sense, it is about asking, How do I fit in? Read full post here. in Editors' Choice Academic Publishing, information theory, literary studies, […]