
Measuring Bias in Literary Classification
I have a new paper out with former student Sunyam Bagga for the latest proceedings of the Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LatechCLFL). For those who are working on computational text analysis of historical documents I really recommend this workshop. It’s a supportive group of folks from both CS and the humanities and the work is increasingly relevant for cultural analytics.
Our paper addresses the problem of biased training data for large-scale automated text classification. What this means is that let’s say you want to find certain kinds of documents in a large heterogenous historical collection. Because this data is very likely un-annotated, you will build “training data” yourself. While a “random sample” should in theory be “unbiased”, i.e. capture the diversity of elements within the overall collection, because we are dealing with such small numbers and because the distributions of those elements in the larger collection are so unknown, the chances that your small training data won’t contain bias is very low.
So our question was, well, what if we knew there was bias in our training data, how much would this be amplified when we go classifying works at larger scale? NLP research has shown just how quickly and awfully bias gets magnified when algorithms are applied. We wanted to see what might happen with a particular case study of predicting fiction from a pool of texts.
To do so, we tested three kinds of bias: genre biases, stylistic biases (specifically dialogue), and gender biases. So what we did was keep the ratios of different features the same in the test data (i.e. the books whose class we would predict), then manipulate the bias in the training data, and then see how much the predictions were impacted by these growing levels of bias.
In other words, imagine if you wanted to predict whether a book was a work of fiction and to learn this category, you increasingly read only science fiction or only mysteries or only romance. But the books you might see to predict could be any of these three categories in equal measure. Or imagine if you only learned fiction written by men but had to discover books written by both men and women? Or finally, what if you only learned that fiction had dialogue (or had no dialogue), would your predictions get worse the more you read from a single category?
The surprising thing we found was that only under the most extreme circumstances (see Fig. 1) did we see any change in the predictive accuracy or balancedness of the classes when we applied either state-of-the-art BERT classification or even SVMs. In other words, for at least this particular goal of predicting whether a book is fiction, deep biases in our training data seemed to have little effect.
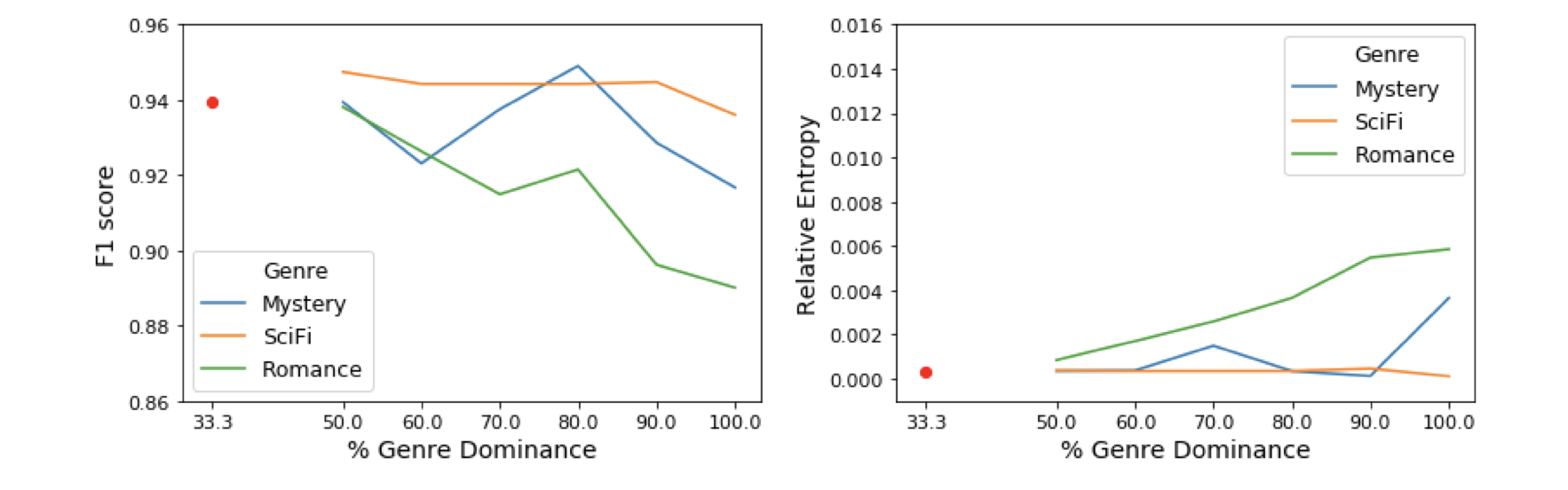
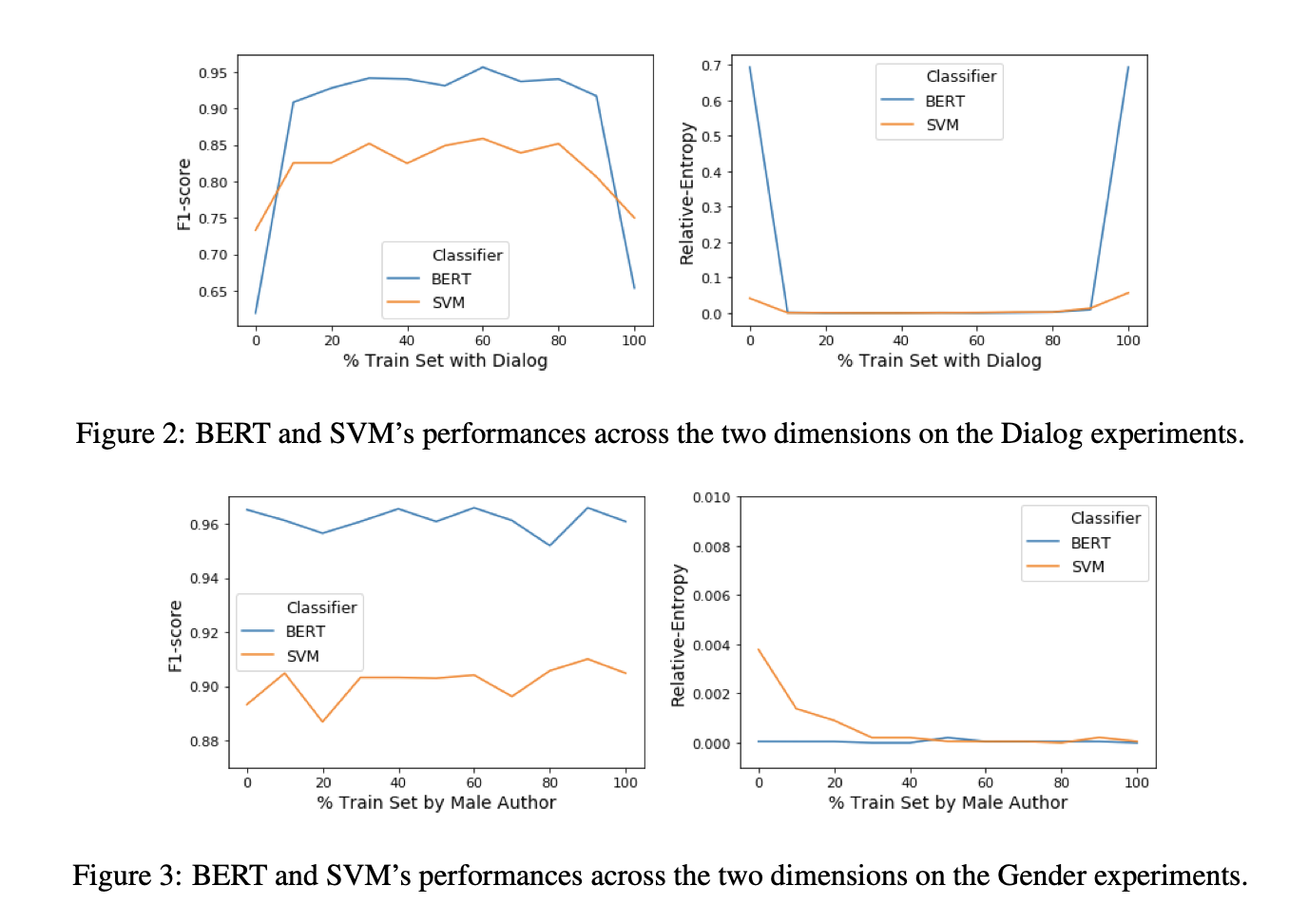
Our takeaway from this is that as long as researchers are careful in producing training data with a semblance of diversity with respect to different qualities of fictional texts, they can be confident that their predictions will not be biased in a meaningful way.
The important caveat here, and it’s a big one, is this does not have any relationship to whether the historical collection itself is “biased.” It just says that for this type of classification we expect to reproduce the underlying distributions of texts as they exist within the larger collection. It can’t fix the fact that those collections may have biases in what was initially collected.
Beyond these individual findings, we think the importance of this paper is in the generalizable model of testing for bias. Detecting whether something is a work of fiction isn’t the only type of classification people studying culture might be interested in. And gender and genre and dialogue aren’t the only features that might contribute to potential downstream biases. We think this framework gives researchers an experimental foundation to continue to better understand where and when bias is a problem and where we can be confident it won’t have subsequent effects.