
Modeling Minor Literature
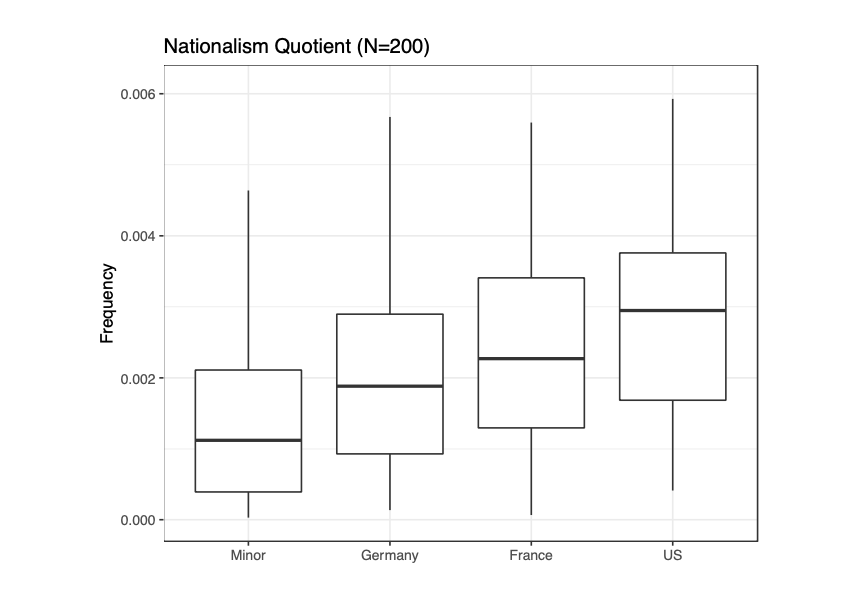
In a recent publication with Matt Erlin, we tested Pascale Casanova’s claim in The World Republic of Letters that literatures associated with minor languages will be more overtly nationalistic in order to gain attention on the world literary stage. We show that despite Casanova’s thesis being likely directionally wrong (minor literatures appear to be less overtly nationalistic, see figure above) her overall theory that minor literatures exhibit distinctive stylistic traits in order to gain international recognition does appear to hold. In other words, not all languages are equal and this impacts what one can say if your audience extends beyond your national borders.
What I liked most about working on this project was the effort to directly test a prominent literary theory. We have an abundance of theories about how literature works but until recently no real way to credibly test them. Our field has been defined by a giant chain of polemics, one after the other. New methods in NLP and machine learning allow us to use data-driven methods to assess the validity of theories under various conditions. (“We can test that!” is one motto in our lab. The other is, “Disappointed, but not surprised”…). Instead of just spinning out your latest idea about capitalism, modernity or, say, minor literature, we can now begin the long and arduous journey towards uncertainty reduction (I won’t say truth, I promise).
I think this piece is a great example of how to do this moving forward. It doesn’t provide the final answer on the topic, but suggests given the data and our way of modeling, we shouldn’t continue to maintain confidence in Casanova’s theory about this particular behaviour of minor literatures. Minor literatures do not look more nationalistic than major literatures. But we should maintain confidence in the stylistic pressures minor literatures are subject to as a function of their minority status.
Another reason I liked this piece is for the opposite reason. We spent a lot of time trying to define and build models of “nationalism.” That was fun and hard in equal measure. But we also spent a lot of time trying to understand what exactly we were modeling and how slippery the idea of “nationalism” is. This ambiguity doesn’t discredit computational approaches. Quite the contrary. It motivates them. Computational approaches require us to define our concepts and terms and thus make our work replicable. This allows others to reproduce our findings, but also alter or modify our methods or data to see how findings evolve under different conditions. Casanova’s work is notable for just how variable the idea of “nationalism” is in a single book. It is many things, but always proves the same point.
In our work, we show how we are capturing a particular idea of nationalism that corresponds with particular literary conventions (in our case explicit v. allegorical nationalism, see the paper for more details). Other kinds of nationalism not captured by our methods are potentially important and can be subject to future investigation, just as other samples of literature may reveal different behaviours at work. In other words, these methods open doors to iterative forms of knowledge.
The correlation between measurements and textual qualities is by far the most exciting aspect of the field for me right now. There are so many opportunities for creative thinking and deep engagements with our objects of study within this process. I really hope others continue to take up this kind of work and put existing theories to the test.