Home
About
Publications
Data Sets
Home
About
Publications
Data Sets
Tag /
machine learning
Loading posts...
Machine Learning and Literary Translation
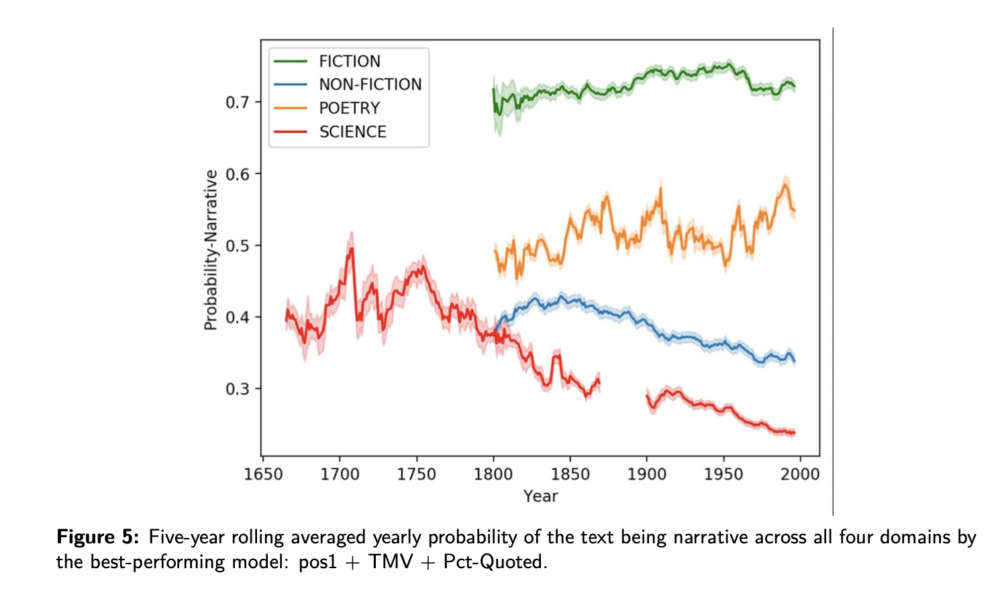
Detecting narrativity across long time scales
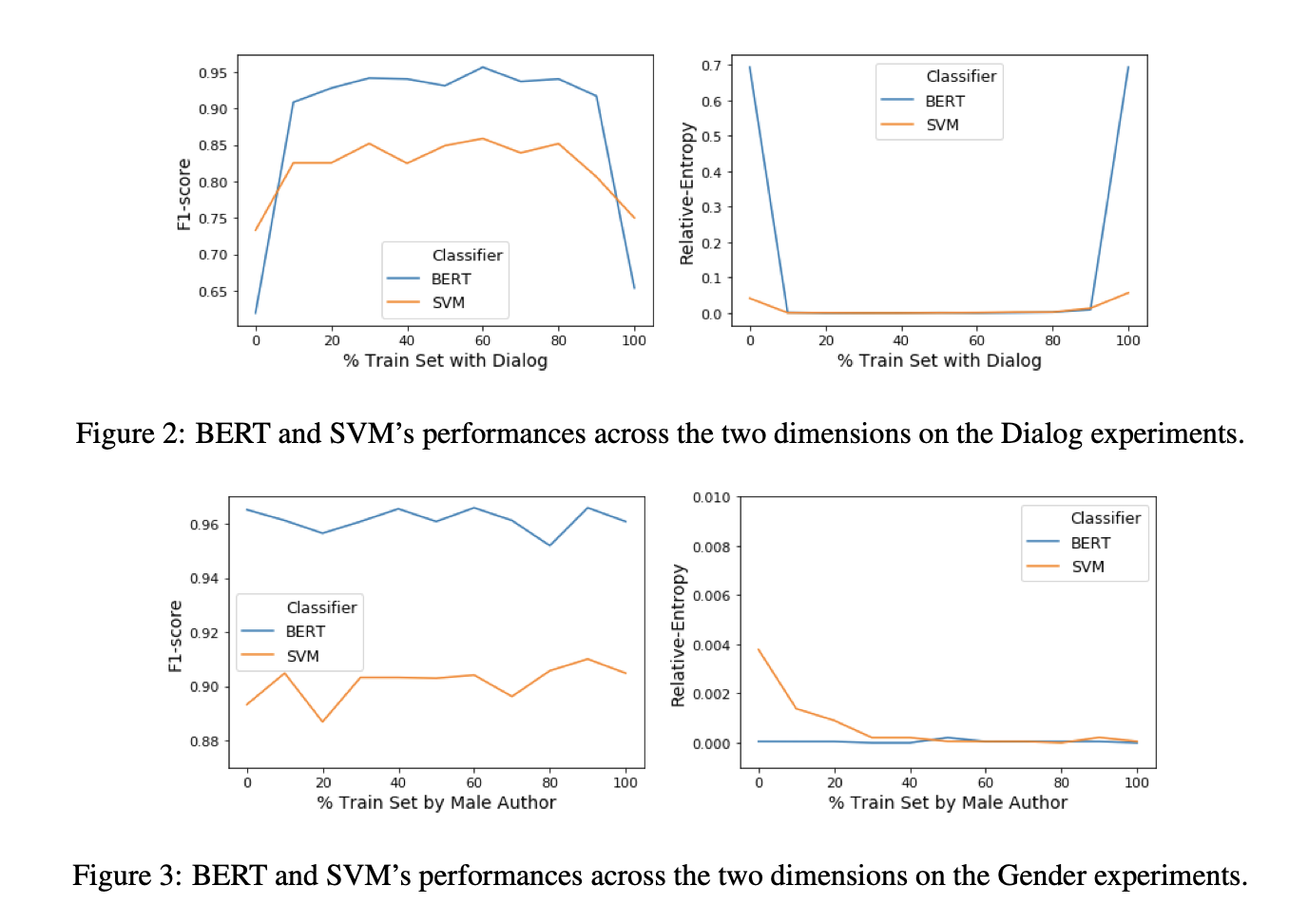
Measuring Bias in Literary Classification
Can We Be Wrong?
Detecting footnotes in 32 million pages of ECCO
1000 Words
AI across the Generations