Machine Learning and Literary Translation
Very excited to announce a new paper on “the predictability of literary translation” as part of the NLP4DH workshop proceedings.
Translation plays an important role in the international circulation of stories and ideas. Translations allow for the more widespread circulation of writing that would otherwise be hindered by global language differences. As such, translations can provide insights not only into the global commerce of ideas, but also the ways in which local regional cultures represent world cultures through their selection of works for translation.
Prior work in computational linguistics has shown that translations are detectable through distinctive linguistic features due to the cognitive pressures on authors moving between languages (often called translationese). We wanted to test whether translations also function more like a literary genre, focusing on distinctive topics or themes that introduce novel experiences into target language literatures.
To do so, constructed a parallel corpus of ~ 21,000 documents drawn from the Hathi Trust Digital Library split between fiction originally written in English and translations of fiction into English from over 120 different languages. Our goal was to test whether we could build a classifier to predict translations based only on content words (not translationese) while masking geographically distinct words (like Paris, Sir, Madame, etc.).
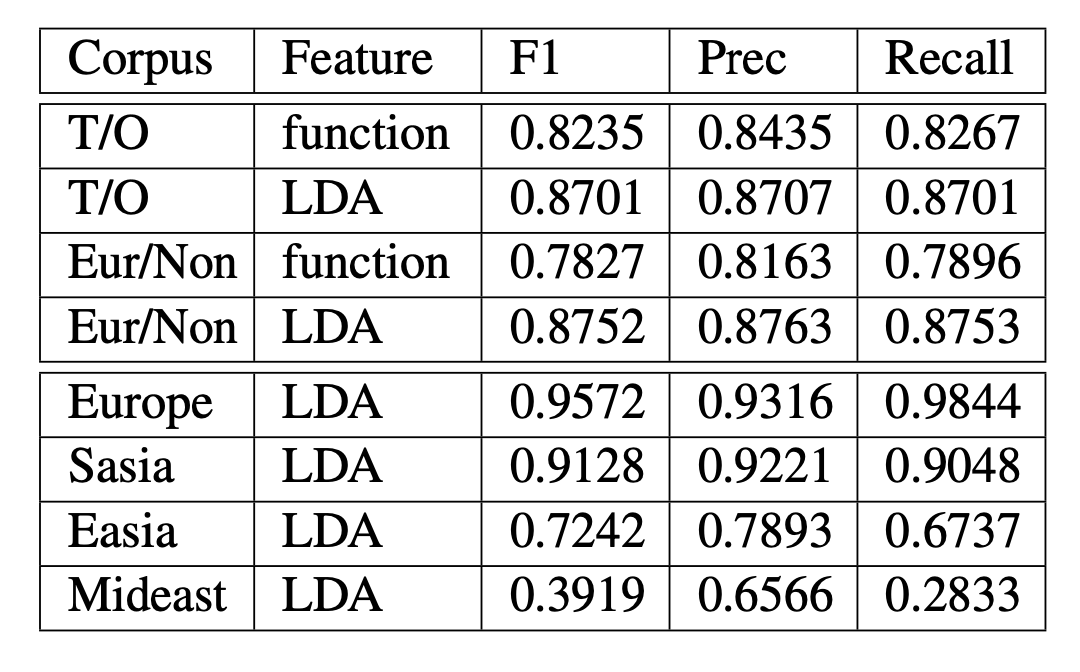
We found that representing our documents using a topic model with geographic words removed still allowed for very high levels of predictability. Not only did translations exhibit distinctive topics, but we also found that the translations’ region of origin was also predictable with a good degree of accuracy (see Table below).
This suggests to us that translations do indeed serve as a literary genre introducing novel narrative experiences into target literary cultures. While the topic of future work, initial inspection of the data suggests that the thematic distinctiveness of translations are strongly driven by regional stereotypes. More work to come!