Home
About
Publications
Data Sets
Home
About
Publications
Data Sets
Tag /
cultural inequality
Loading posts...
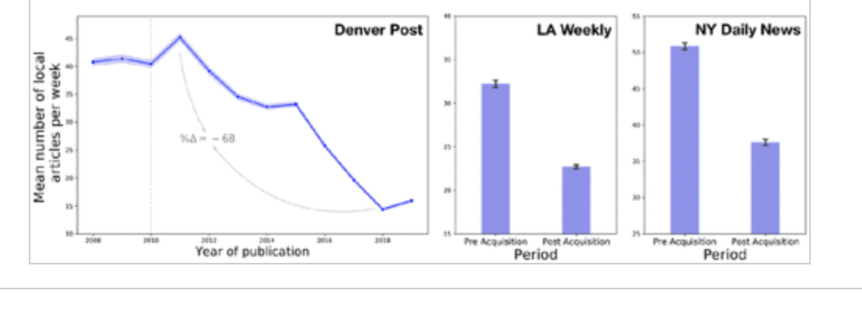
Buying the news
The difference Queer FanFic makes
Let’s talk about debiasing books – Webinar
Social Characters: new lab collaboration by Eve Kraicer
Detecting gender in 26,000 literary characters
Congratulations to Victoria Svaikovsky ARIA Intern for 2017
On Prestige Bias in the Chronicle of Higher Ed
The Prestige Trap
1
2
Next